Pump Prime
One pioneering approach that showed enormous success is the Pump Priming Programme. While providing money for travel and secondments is always effective, there is nothing like the opportunity for research funding to focus the minds of academics. Knowledge 4 All continues its role of a mini funding agency and encouraged its members and others outside the field to collaborate and perform exciting new research together by supporting a series of preliminary investigations in areas of interest to the network.
Learning and Inference in Structured, Higher Dimensional Stochastic Differential Systems
There are many areas of scientific research, business analysis and engineering for which stochastic differential equations are the natural form of system model. Fields such as environmental modelling, systems biology, ecological systems, weather, market dynamics, traffic networks, neural modelling and fMRI are all areas which have regularly used stochastic differential equations for describing system dynamics and making predictions. In these same areas, ever-increasing data quantities are becoming available, and there is a demand to utilise this data to refine and develop good system models. However it is very rare for this data to be directly used to develop stochastic differential models. Where stochastic differential equations are used, simulation methods still seem to be the standard modelling approach. Downloadable or purchasable tools for utilising inference and learning in these continuous-time and nonlinear systems are currently unavailable. The long-term aim of this research agenda is to develop, implement and promote tools for practical data-driven modelling for continuous-time stochastic systems. The focus is on inference and learning in high dimensional, nonlinear stochastic differential systems. We aim to make stochastic differential modelling as easy to do as simulation of stochastic differential equations (SDEs), fixed time modelling or deterministic methods. The immediate goal of this pump priming proposal was to coordinate, focus and develop existing independent early efforts in this direction at the three sites that form part of this proposal. We provided a coherent framework and test environment for the collaborative research. We researched, developed and firmly established a baseline set of methods for stochastic differential inference and learning. We proved the benefits and feasibility of these methods within the test environment, and provided clear demonstrations of the capabilities. This provided an initial toolset for stochastic modelling, and a firm grounding for establishing a larger scale European collaborative research agenda in this area.
Modelling Learning and Co-Learning Curves for Application to Cognitive-Interfaces
This project studied learning curves in multi-component systems, with a special focus on the situation where humans and machines interact via an adaptive interface. In this situation a system is formed by multiple adaptive components that need to learn how to optimise the system’s overall behaviour: each component learns to behave so as to achieve the system’s optimum. A special application is human-machine interaction, where both the users and the interfaces are trying to maximise information flow, by adapting to each other. This includes issues of co-learning, co-operation; concept tracking; exploration-exploitation. The presence of delayed, partial, noisy rewards is a necessary part of this scenario. The case of N=2 components was emphasised, to identify the various modalities of learning, before any attempt was made to model the N>2 case. We modelled various settings, including active, reinforcement, online and learning from independent and identically distributed data, in various conditions. The theoretical results were compared with experimental learning curves, obtained both for machine learning algorithms, and for humans engaged in various tasks (e.g., extensive data from Microsoft Research about users learning in various games on the Xbox; and web logs of users interacting with interfaces; also learning curves from neuroscience literature). Finally, we transferred our models to the task of designing cognitive interfaces, to deal with one or more users, in an adaptive way, including the scenario of interaction within online social tagging communities, and various other web based co-operation and co-learning settings.
Context Models for Textual Entailment and their Application to Statistical Machine Translation
Machine Translation systems frequently encounter terms they are not able to translate appropriately. Assume for example, that an SMT system translating Fujitsu has filed a lawsuit against Tellabs for patent infringement is missing the phrases:“filed a lawsuit against” in its phrase table. A previously suggested solution is to paraphrase (e.g. to: “sued”), and then to translate the paraphrased sentence. In this work we suggest a novel solution taking place when a paraphrase is not available: By translating a sentence whose meaning is entailed by the original one, we may lose some information, yet produce a useful translation nonetheless: “Fujitsu has accused Tellabs for patent infringement”. Textual Entailment provides an appropriate framework for handling both these solutions through the use of entailment rules. We thus propose a first application of this paradigm for SMT, with a primary focus on context models. While verifying the validity of the context for a rule application is a key issue, little work has been done in that area beyond the single word level typically address in WSD tasks. To address this issue, we develop probabilistic context models for semantic inference in general and to apply them specifically in SMT setting, thus exploiting Bar Ilan’s and XRCE’s expertise in these fields.
Semi-supervised learning of semantic spatial concepts for a mobile robot

The ability of building robust semantic space representations of environments is crucial for the development of truly autonomous robots. This task, inherently connected with cognition, is traditionally achieved by training the robot with a supervised learning phase. This work argues that the design of robust and autonomous systems would greatly benefit from adopting a semi-supervised online learning approach. Indeed, the support of open-ended, lifelong learning is fundamental in order to cope with the dazzling variability of the real world, and online learning provides precisely this kind of ability. The research focused on the robot place recognition problem, and designed online categorization algorithms that occasionally ask for human intervention based on a confidence measure. By modulating the number of queries on the experienced data sequence, the system adaptively trades off performance with degree of supervision. Through a rigorous analysis, simultaneous performance and query rate guarantees are proven in extremely robust (game-theoretic) data generation scenarios. This theoretical analysis is supported and complemented by extensive evaluation on data acquired on real robotic platforms.
Sparse Reinforcement Learning in High Dimensions 1

With the explosive growth and ever increasing complexity of data, developing theory and algorithms for learning with high-dimensional data has become an important challenge in statistical machine learning. Although significant advances have been made in recent years, most of the research efforts have been focused on supervised learning problems. This project designed, analysed, and implemented reinforcement learning algorithms for high-dimensional domains. We investigated the possibility of using the recent results in l1-regularization and compressive sensing in reinforcement learning. Humans learn and act using complex and high-dimensional observations and are extremely good in knowing how to dispense of most of the observed data with almost no perceptual loss. Thus, we hope that the generated results can shed some light on understanding of human decision-making. Our main goal was to find appropriate representations for value function approximation in high-dimensional spaces, and to use them to develop efficient reinforcement learning algorithms. By appropriate we mean representations that facilitate fast and robust learning, and by efficient we mean algorithms whose sample and computational complexities do not grow too rapidly with the dimension of the observations. We further intend to provide theoretical analysis for these algorithms as we believe that such results will help us refine the performance of such algorithms. Finally, we intend to empirically evaluate the performance of the developed algorithms in real-world applications such as a complex network management domain and a dogfight flight simulator.
Data-Dependent Geometries and Structures : Analyses and Algorithms for Machine Learning
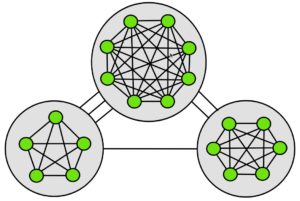
A standard paradigm of supervised learning is the data-independent hypothesis space. In this model a data set is a sample of points from some space with a given geometry. Thus the distance between any two points in the space is independent of the particular sample. In a data-dependent geometry the distance depends on the particular points sampled. Thus for example consider a data set of “news stories,” containing a story in the Financial Times about a renewed investment in nuclear technology, and a story in the St. Petersburg Gazetteer about job losses from a decline in expected tourism. Although these appear initially to be dissimilar, the inclusion of a third story regarding an oil pipeline leakage creates an indirect “connection.” In the data-independent case the “distance” between stories is unchanged while in the data-dependent case, the distances reflect the connection. This project was designed to address the challenges posed both algorithmically and theoretically by data-defined hypothesis spaces. This project brought together three sites to address an underlying theme of the PASCAL2 proposal that of leveraging prior knowledge about complex data. The complexity of real world data is clearly offset by its intricate geometric structure – be it hierarchical, long-tailed distributional, graph based, and so forth. By allowing the data to define the hypothesis space we may leverage these structures to enable practical learning – the core aim of this project. This three-way collaboration was thought likely to give rise to a wide spectrum of possible applications, fostering future opportunities for joint research activities.
Online Learning for Robot Control
Precise models of technical systems and the task to be accomplished can be crucial in technical applications. In robot tracking control, only a well-estimated inverse dynamics model results in both high accuracy and compliant, low-gain control. For complex robots such as humanoids or lightweight robot arms, it is often hard to analytically model the system sufficiently well and, thus, modern regression methods can offer a viable alternative. Current regression methods such as Gaussian process regression or locally weighted projection regression either have high computational cost or are not straightforward to use (respectively). Hence, task-appropriate real-time methods are needed in order to achieve high performance. This project uses the large body of insights from modern online learning methods and applied them in the context of robot learning. Particularly, we focussed on three novel problems that have not yet been tackled in the literature. The first two problems are in the learning of inverse dynamics domain: current methods largely neglect the existence of input noise and only focus on output noise. We considered both sources of noise together. This may have far reaching consequences: the input noise only exists in training data while in the recall or control case it no longer occurs. Secondly, we studied the bias originating from the active data generation that is part of the online learning problem. Our intention was to build on recent advances in online learning algorithms, such as the confidence-weighted algorithm (CW) and the adaptive-regularization-algorithm (AROW), and design, analyze and experiment new techniques and method to cope with the above challenges. Success will allow us to build better robot controllers for smooth and delicate robot dynamics.
Bridging machine classification and human cognition: discriminative vs. generative learning

Classification, one of the most widely studied problems in machine learning, is also a central research topic in human cognitive psychology. So far these two parallel fields have mostly developed in isolation. Our research bridges machine learning with human psychology research by investigating discriminative vs. generative learning in humans. The distinction between discriminative and generative approaches is much studied in machine learning, but has not been examined in human learning. Discriminative learners find a direct mapping between inputs and class labels whereas generative learners model a joint distribution between inputs and labels. These approaches often result in classification differences. Our preliminary work indicated that humans can be prompted to adopt discriminative or generative approaches to learning the same dataset. In this work we conducted experiments in which we measured learning curves of humans who are trained on datasets under discriminative vs. generative learning conditions. We used datasets which have been previously used as machine learning benchmarks and also datasets of brain imaging scans used for medical diagnosis. Humans still outperform the most powerful computers in many tasks, such as learning from small amounts of data and comprehending language. Thus, insights from human learning have great potential to inform machine learning. An understanding of how humans solve the classification problem will be instructive for machine learning in several ways: for the many situations where humans still outperform computers, human results can set benchmarks for machine learning challenges. Additionally, understanding human learning approaches can help give direction to the machine learning approaches that will have the most potential. Finally, in many situations we want machines to behave like humans in order to facilitate human computer interactions. An understanding of human cognition is important for developing machines that think like humans.
Sparse Reinforcement Learning in High Dimensions 2
Although significant advances in learning with high-dimensional data have been made in recent years, most of the research efforts have been focused on supervised learning problems. We propose to design, analyze, and implement reinforcement learning algorithms for high-dimensional domains. We will investigate the possibility of using the recent results in l1-regularization and compressive sensing in reinforcement learning. Humans learn and act using complex and high-dimensional observations and are extremely good in knowing how to dispense of most of the observed data with almost no perceptual loss. Thus, we hope that the generated results can shed some light on understanding of human decision-making.
Normalised Compression Distance Measures and Their Application in Unsupervised and Supervised Analysis of Polymorphic Data
 The project researchers have built a generic open-source software package (Complearn) for building tree structured representations from normalised compression distance (NCD) or normalised Google distance (NGD) distance matrix. Preliminary empirical tests with the software have indicated that the data representation is crucial for the performance of the algorithms, which led us to further study applications of lossy compression algorithms (audio stream to midi and lossy image compression through wavelet transformation). In the second part of the project, the methods and tools developed in the project were applied in a challenging and exciting real-world problem. The goal was to recover the relations among different variants of a text that has been gradually altered as a result of imperfectly copying the text over and over again. In addition to using the currently available methods in Complearn, we also developed a new compression-based method that is specifically designed for stemmatic analysis of text variants.
The project researchers have built a generic open-source software package (Complearn) for building tree structured representations from normalised compression distance (NCD) or normalised Google distance (NGD) distance matrix. Preliminary empirical tests with the software have indicated that the data representation is crucial for the performance of the algorithms, which led us to further study applications of lossy compression algorithms (audio stream to midi and lossy image compression through wavelet transformation). In the second part of the project, the methods and tools developed in the project were applied in a challenging and exciting real-world problem. The goal was to recover the relations among different variants of a text that has been gradually altered as a result of imperfectly copying the text over and over again. In addition to using the currently available methods in Complearn, we also developed a new compression-based method that is specifically designed for stemmatic analysis of text variants.
The various methods developed in the project were applied and tested using the tradition of the legend of St. Henry of Finland, which forms a collection of the oldest written texts found in Finland. The results were quite encouraging: the obtained family tree of the variants, the stemma, corresponds to a large extent with results obtained with more traditional methods (as verified by the leading domain expert, Tuomas Heikkilä Ph.D., Department of History, University of Helsinki). Moreover, some of the identified groups of manuscripts are previously unrecognised ones. Due to the impossibility of manually exploring all plausible alternatives among the vast number of possible trees, this work is the first attempt at a complete stemma for the legend of St. Henry. The new compression-based methods developed specifically for the stemmatology domain will be released in the future as part of the open-source Complearn package. We are also considering the possibility of creating a Pascal challenge using this type of data.
Learning with Labeled and Unlabeled Data
Semi-supervised learning belongs to the main directions of the recent machine learning research. The exploitation of the unlabeled data is an attractive approach either to extend the capability of the known methods or to derive novel learning devices. Learning a rule from a finite sample is the fundamental problem of machine learning. For this purpose two resources are needed: a big enough sample and enough computational power. While the computational power has been growing rapidly, the cost of collecting a large sample remains high since it is labour intensive. The unlabeled data can be used to find a compact representation of the data which preserves as much as possible its original structure.
Dynamics and Uncertainty in Interaction
This PASCAL funded pump-priming project aims to bring continuous and uncertain interaction methods into both brain-computer interfaces, and to the interactive exploration of song spaces. By treating the interaction problem as a continuous control process, a range of novel techniques can be brought to bear on the BCI and song exploration problem. EEG brain-computer interfaces suffer from high noise levels and heavily-lagged dynamics. Existing user interface models are inefficient and frustrating for interaction. By explictly taking the noise and dynamical properties of the BCI control signals into account, more suitable interfaces can be devised. The song-exploration problem involves navigation of very high-dimesional feature spaces. The mapping from these spaces to user intention is uncertain. Uncertain and predictive displays, combined with intelligent navigation controls, can aid users in intuitively navigating musical spaces. This work is in collaboration with the IDA group at Fraunhofer First and the Intelligent Signal Processsing Group at DTU.
Large Margin Algorithms and Kernel Methods for Speech Recognition
Research on large margin algorithms in conjunctions with kernel methods has been both exciting and successful. While there have been quite a few preliminary successes in applying kernel methods for speech applications, most research efforts have focused on non-temporal problems such as text classification and optical character recognition (OCR). We propose to design, analyze, and implement learning algorithms and kernels for hierarchical-temporal speech utterances. Our first and primary end-goal is to build and test thoroughly a full-blown speech phoneme classifier that will be trained on millions of examples and will achieve the best results in this domain. This project is a joint reseach effort between The Hebrew University and IDIAP.
>Multi-Task Learning: Optimisation Methods and Applications
This project is focused on multi-task learning (MTL) for the purposes of developing optimisation methods, statistical analysis and applications. On the theoretical side, we propose to develop a new generation of MTL algorithms; on the practical side, we will explore applications of these algorithms in the areas of marketing science, bioinformatics and robot learning. As an increasing number of data analysis problems require learning from multiple data sources, MTL should receive more attention in Machine Learning and we expect that more researchers will work on this topic in the coming years. We are particularly interested in optimisation approaches to MTL. In particular, our proposed approach will: 1) allow one to model constraints among the tasks; 2) allow semi-supervised learning — only some of the tasks have available data but we still wish to learn all tasks; 3) lead to efficient optimisation algorithms; 4) subsume related frameworks such as collaborative filtering and learning vector fields.
Online Performance of Reinforcement Learning with Internal Reward Functions
 We consider reinforcement learning under the paradigm of online learning where the objective is good performance during the whole learning process. This is in contrast to the typical analysis of reinforcement learning where one is interested in learning a finally near-optimal strategy. We will conduct a mathematically rigorous analysis of reinforcement learning under this alternate paradigm and expect as a result novel and efficient learning algorithms. We believe that for intelligent interfaces the proposed online paradigm provides significant benefits as such an interface would deliver reasonable performance even early in the training process. The starting point for our analysis will be the method of upper confidence bounds which has already been very effective for simplified versions of reinforcement learning. To carry the analysis to realistic problems with large or continuous state spaces we will estimate the utility of states by value function approximation through kernel regression. Kernel regression is a well founded function approximation method related to support vector machines and holds significant promise for reinforcement learning. Finally we are interested in methods for reinforcement learning where no or only little external reinforcement is provided for the learning agent. Since useful external rewards are often hard to come by, we will investigate the creation of internal reward functions which drive the consolidation and the extension of learned knowledge, mimicking cognitive behaviour.
We consider reinforcement learning under the paradigm of online learning where the objective is good performance during the whole learning process. This is in contrast to the typical analysis of reinforcement learning where one is interested in learning a finally near-optimal strategy. We will conduct a mathematically rigorous analysis of reinforcement learning under this alternate paradigm and expect as a result novel and efficient learning algorithms. We believe that for intelligent interfaces the proposed online paradigm provides significant benefits as such an interface would deliver reasonable performance even early in the training process. The starting point for our analysis will be the method of upper confidence bounds which has already been very effective for simplified versions of reinforcement learning. To carry the analysis to realistic problems with large or continuous state spaces we will estimate the utility of states by value function approximation through kernel regression. Kernel regression is a well founded function approximation method related to support vector machines and holds significant promise for reinforcement learning. Finally we are interested in methods for reinforcement learning where no or only little external reinforcement is provided for the learning agent. Since useful external rewards are often hard to come by, we will investigate the creation of internal reward functions which drive the consolidation and the extension of learned knowledge, mimicking cognitive behaviour.
CARTER
The goal of this project is to investigate whether image representations based on local invariant features, and document analysis algorithms such as probabilistic latent semantic analysis, can be successfully adapted and combined for the specific problem of scene categorisation. More precisely, our aim is to distinguish between indoor/outdoor or city/landscape images, as well as (in a later stage) more diverse scene categories. This is interesting in its own right in the context of image retrieval or automatic image annotation, and also helps to provide context information to guide other processes such as object recognition or categorisation. So far, the intuitive analogy between local invariant features in an image and words in a text document has only been explored at the level of object rather than scene categories. Moreover, it has mostly been limited to a bags-of-keywords representation. Introducing visual equivalents for more evolved text retrieval methods to deal with word stemming, spatial relations between words, synonyms and polysemy is the prime research objective of this project, as well as studying the statistics of the extracted local features to determine to which degree the analogy between local visual features and words really holds in the context of scene classification, or how the local features based description needs to be adapted to make it hold.
Next Generation Information Retrieval
Semantic information recognition and extraction is the major enabler for next generation information retrieval and natural language processing. Yet it is currently only successful in small domains of limited scope. We claim that to move beyond this restriction requires one: (1) to perform integrated semantic extraction incorporating a probabilistic representation of semantic content, and (2) to better employ the broader semantic resources now coming on-line. This project will explore both fundamental research and large scale applications, using the public domain Wikipedia as a driver and a resource. Research will explore the integration of semantic information into the language processing chain. Applications will employ this in broad spectrum named-entity recognition, and in cross-lingual information retrieval using the rich but incomplete data available fron the Wikipedia. Three PASCAL sites will contribute pre-existing software, theory, and skills to the range of tasks involved.
GISK
The purpose of the project is to explore a new family of grammatical inference algorithms, based on the use of string kernels. These algorithms are capable of efficiently learning some languages that are context sensitive, including many linguistically interesting examples of mildly context sensitive languages. The project started on November 1st 2005, and finished at the end of October 2006. It is a collaboration between Royal Holloway and EURISE.
Methods for fusing eye movements and text content for information retrieval
This project develops new kinds of information retrieval systems, by fusing multimodal implicit relevance feedback data with text content using Bayesian and kernel-based machine learning methods. A long term goal of information retrieval is to understand the “user’s intent”. We will study the feasibility of directly measuring the interests at the sentence level, and of coupling the results to other relevant sources to estimate user preferences. The concrete task is to predict relevance for new documents given judgments on old ones. Such predictions can be used in information retrieval, and the most relevant documents can even be proactively offered to the user. The motivation for this project is that by using eye movements we wish to get rid of part of the tedious ranking of retrieved documents, called relevance feedback in standard information retrieval. Moreover, by using the potentially richer relevance feedback signal we want to access more subtle cues of relevance in addition to the usual binary relevance judgments. The major task in this research is to improve the predictions by combining eye movements with the text content. We aim at combining the relevance feedback to textual content to infer relevant words, concepts, and sentences. We combine two data sources for predicting relevance: eye movements measured during reading and the text content. This is challenging: time series models of very noisy data need to be combined with text models in a task where we typically only have very little data about relevance available. This novel research task involves dynamic modeling of noisy signals, modeling of large document collections and users’ interests, and information retrieval. Multimodal integration and natural language processing are needed to some extent as well. The project also involves a number of interesting challenges from the point of view of applying both kernel and Bayesian methods.