Finding Patterns in Media
The world has gone digital in a big way. Newspapers, television channels, tweeters, bloggers. We’re starting to drown in data, and much of that data is trivia. Today, information is no longer informative. When scintillation swamps science already, will this world of swirling numbers result in white noise for all? What we need is an automated intelligence to make sense of the digital hubbub, to hear the majority voices amongst the crowds.

In this Internet age, Machine Learning and AI are finally coming of age. At last these adaptive algorithms have access to a digital world that is becoming as complex, noisy and everchanging as the real world it reflects. New intelligent behaviours can be derived from combinations of statistical and algorithmic approaches, designed specifically for these vast unexplored dataspheres. Computers can now find their own data, process, cluster and learn autonomously. By doing so they can make discoveries that reflect new understandings of our own world.
As a student, Nello Cristianini worked as a journalist. In his spare time he enjoyed browsing old newspapers. As he read and thought about the events of the period, he started to realise the impact of this media. “I became very acutely aware of how the contents of the media both reflect and affect society,” says Cristianini. Today Cristianini is Professor of Artificial Intelligence at University of Bristol. He focusses on the automatic analysis of large and diverse sources of data. “It was just natural to think about automating the analysis of contents of the whole mediasphere,” he says. “It put me in a place between the sciences and the humanities, which is a place of comfort for me. And it is something that people needed to do anyway.”
The research group has made it their business to ask the questions that no-one else asks. “Companies like Google can work at bigger scales, but do not ask the kinds of questions we ask about social science, “ says Cristianini. “On the other hand, social scientists are very interested in these questions, but cannot work at this scale and with this sophistication. This is where we came in, combining state-of-the-art text mining with big data. We designed all experiments in collaboration with social scientists.”
 The group uses a range of techniques to achieve their results. These are integrated as modules into NOAM: the News Outlets Analysis and Monitoring System. NOAM is a computational infrastructure which is capable of gathering, storing, translating, annotating and visualising vast amounts of news items and social media content. It combines a relational database with state of the art AI technologies, including data mining, machine learning and natural language processing. These technologies are organised in a distributed architecture of collaborating modules, that are used to populate and annotate the database (see box). The system manages tens of millions of news items in multiple languages, automatically annotating them in order to enable queries based on their meanings. It now tracks 1,100 news outlets in 22 languages, and tweets from 54 UK locations. Overall the system has generated over one Terabyte (equivalent to 1000 Gigabytes) of data over the past four years.
The group uses a range of techniques to achieve their results. These are integrated as modules into NOAM: the News Outlets Analysis and Monitoring System. NOAM is a computational infrastructure which is capable of gathering, storing, translating, annotating and visualising vast amounts of news items and social media content. It combines a relational database with state of the art AI technologies, including data mining, machine learning and natural language processing. These technologies are organised in a distributed architecture of collaborating modules, that are used to populate and annotate the database (see box). The system manages tens of millions of news items in multiple languages, automatically annotating them in order to enable queries based on their meanings. It now tracks 1,100 news outlets in 22 languages, and tweets from 54 UK locations. Overall the system has generated over one Terabyte (equivalent to 1000 Gigabytes) of data over the past four years.
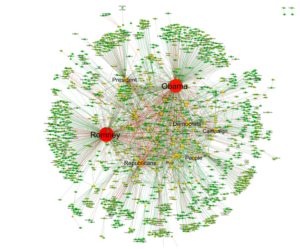
This extraordinary data combined with machine learning has enabled the group to make new analyses of the media as it changes. In one study, articles relating to the 2012 US elections were investigated. Support Vector Machines were used to identify articles relating to the topic, actors were identified from subject-verb-object triplets and key actors and actions were identified using statistical analysis and classified into endorsement and opposition. The key actors and actions form a network of the election, with the key protoganists Obama and Romney clearly visible.
In another study, the team investigated the differences in reporting style and content of nearly 500 English-language online news outlets over 10 months. 2.5 million articles were analysed with some surprising results. The topics, the people mentioned and their gender, readability (a function of the length of sentences and the number of syllables in the words) and subjectivity (the number of emotional adjectives) were measured. The analysis showed that certain tabloid papers were extremely easy to read and highly subjective while broadsheet papers tended to be harder to read and more objective. More surprisingly, the gender bias of the articles was marked. For example, in articles relating to sport news, men were eight times more likely to be mentioned. Only in fashion news were men and women more equally described.
What has captured the interest of global media has been our analysis of Twitter content.
Cristianini is passionate about the work. “We were able to measure patterns of media-content similarity across the 27 EU countries; detect gender bias in the media, compare the readability of various newspapers; extract the key political relations among actors in the US Elections,” he says. ”But what has captured the interest of global media has been our analysis of Twitter content.”
This recent analysis focussed on public sentiment. Traditionally, the only way to assess the mood of the general public was to question a large number of people about their feelings. Cristianini’s team decided to focus on Twitter – commonly used by people to express their feelings on everything and anything. 484 million tweets that were generated by more than 9.8 million users were collected from the 54 largest cities in the UK between July 2009 and January 2012. Their system tracked four moods: “Fear”, “Joy”, “Anger” and “Sadness” by counting frequencies of words associated with each mood in the tweets. Using this method they recorded the changes in moods in different UK cities over time.
The results were fascinating. There was a periodic peak of joy around Christmas and a periodic peak of fear around Halloween. Negative moods started to dominate the Twitter content after the announcement of massive cuts in public spending on October 2010, with the effect continuing from then onwards. Most interestingly, there was a significant increase in anger in the weeks before the summer riots of August 2011. There was also a possible calming effect coinciding with the run up to the royal wedding. Perhaps ironically, these research results became big news, reported in media around the world. Social scientists have found the work of great interest. “We have been in touch with various social scientists,” says Cristianini, “many of whom are both fascinated and slightly worried about the possibilities. We are now collaborating with some of them.”
The future looks bright for this technology. Cristianini has big ambitions. “With the right amount of funding, we could monitor topics and sentiment in all key news outlets as well as radio stations,” he says. “We could probably access information in images too. There is a lot that would be exciting to do.”
News Outlets Analysis and Monitoring System
NOAM is centred around a database, which is populated by a web pipeline and by a statistical machine translation module, operating on multilingual news content. It is a data management system that autonomously generates parts of its contents, for example by translation and annotation. Its architecture is modular, with modules including:
- Pre-defined lists of news feeds are crawled, in RSS or Atom format, to provide the content of news outlets of interest. News feeds contain links to the article bodies. An HTML scraper identifies and collects the textual article content from each of the article webpages. The crawler tags these newly discovered articles with a set of tags that will enable other modules to work on them, such as the language of article.
- All non-English articles are translated into English using a statistical machine translation approach. Currently all 21 main EU languages are translated.
- Topic Taggers. The topic of articles is discovered using topic classification based on Support Vector Machines.
- Articles are clustered into stories (sets of articles that discuss the same event).
- Suffix Tree. Frequent phrases (memes) and significant events are detected using a suffix tree.
- Entities Detection. Named entities present in articles are detected (people, organisations and locations).
- Feed Finder. The addition of new feeds into the system is performed in a semi-automatic way. This module crawls the Internet and tries to discover new outlets and corresponding feeds. The outlets and feeds have to be confirmed and annotated manually for addition to the system.