On social media, Arabic speakers tend to express themselves in their own local dialect. To do so, Tunisians use “Tunisian Arabizi”, which consists in supplementing numerals to the Latin script rather than the Arabic alphabet.
In the African continent, analytical studies based on Deep Learning are data hungry. To the best of our knowledge, no annotated Tunisian Arabizi dataset exists.
Twitter, Facebook and other micro-blogging systems are becoming a rich source of feedback information in several vital sectors, such as politics, economics, sports and other matters of general interest. Our dataset is taken from people expressing themselves in their own Tunisian Dialect using Tunisian Arabizi.
TUNIZI is composed of one instance presented as text comments collected from Social Media, annotated as positive, negative or neutral. This data does not include any confidential information. However, negative comments may include offensive or insulting content.
TUNIZI dataset is used in all iCompass products that are using the Tunisian Dialect. TUNIZI is used in a Sentiment Analysis project dedicated for the e-reputation and also for all Tunisian chatbots that are able to understand the Tunisian Arabizi and reply using it.
Team
TUNIZI Dataset is collected, preprocessed and annotated by iCompass team, the Tunisian Startup speciallized in NLP/NLU. The team composed of academics and engineers specialized in Information technology, mathematics and linguistics were all dedicated to ensure the success of the project. iCompass can be contacted through emails or through the website: www.icompass.tn
Implementation
Data Collection: TUNIZI is collected from comments on Social Media platforms. All data was directly observable and did not require other data to be inferred from. Our dataset is taken from people expressing themselves in their own Tunisian Dialect using Arabizi. This dataset relates directly to Tunisians from different regions, different ages and different genders. Our dataset is collected anonymously and contains no information about users identity.
Data Preprocessing & Annotation: TUNIZI was preprocessed by removing links, emoji symbols and punctuation. Annotation was then performed by five Tunisian native speakers, three males and two females at a higher education level (Master/PhD).
Distribution and Maintenance: TUNIZI dataset is made public for all upcoming research and development activitieson Github. TUNIZI is maintained by iCompass team that can be contacted through emails or through the Github repository. Updates will be available on the same Github link.
Conclusion: As the interest in Natural Language Processing, particularly for African languages is growing, a natural future step would involve building Arabizi datasets for other underrepresented north African dialects such as Algerian and Moroccan.
We set out with a novel idea; to develop an application that would (i) collect an individual’s Blood Pressure (BP) and activity data, and (ii) make future BP predictions for the individual with this data.
Key requirements for this study therefore were;
The ability to get the BP data from an individual.
The ability to get a corresponding record of their activities for the BP readings.
The identification of a suitable Machine Learning (ML) Algorithm for predicting future BP.
Dr. Moses Thiga, Kabarak University, School of Science, Engineering and Technology
Ms. Daisy Kiptoo, Kabarak University, School of Science, Engineering and Technology
Dr. Pamela Kimeto, Kabarak University, School of Medicine and Health Sciences
Pre-test the idea – Pre testing the idea was a critical first step in our process before we could proceed to collect the actual data. The data collection process would require the procurement of suitable smart watches and the development of a mobile application, both of which are time consuming and costly activities. At this point we learnt our first lessons; (i) there was no precedence to what we were attempting and subsequently (ii) there were no publicly available BP data sets available for use in pre-testing our ideas.
Simulate the test data – The implication therefore was that we had to simulate data based on the variables identified for our study. The variables utilized were the Systolic and Diastolic BP Reading, Activity and a timestamp. This was done using a spreadsheet and the data saved as a comma separate values (csv) file. The csv is a common file format for storing data in ML.
Identify a suitable ML model – The data simulated and that in the final study was going to be time series data. The need to predict both the Systolic and Diastolic BP using previous readings, activity and timestamps meant that we were was handling a multivariate time series data. We therefore tested and settled on an LSTM model for multivariate time series forecasting based on a guide by Dr Jason Browniee (https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/)
Develop the data collection infrastructure – There being no pre-existing data for the development implied that we had to collect our data. The unique nature of our study, collecting BP and activity data from individuals called for an innovative approach to the process.
BP data collection – for this aspect of the study we established that the best way to achieve this would be the use of smart watches with BP data collection and transmission capabilities. In addition to the BP data collection, another key consideration for the device selection was affordability. This was occasioned both by the circumstances of the study, limited resources available and more importantly, the context of use of a probable final solution; the watch would have to be affordable to allow for wide adoption of the solution.
The watch identified was the F1 Wristband Heart and Heart Rate Monitor.
Activity data collection – for this aspect of the study a mobile application was identified as the method of choice. The application was developed to be able to receive BP readings from the smart watch and to also collect activity data from the user.
Test the data collection – The smart watch – mobile app data collection was tested and a number of key observations were made.
Smart watch challenges – In as much as the watch identified is affordable it does not work well for dark skinned persons. This is a major challenge given the fact that a majority of people in Kenya, the location of the study and eventual system use, are dark skinned. As a result we are examining other options that may work in a universal sense.
Mobile app connectivity challenges – The app initially would not connect to the smart watch but this was resolved and the data collection is now possible.
Next Steps
Pilot the data collection – We are now working on piloting the solution with at least 10 people over a period of 2 – 3 weeks. This will give us an idea on how the final study will be carried out with respect to:
How the respondents use the solution,
The kind of data we will be able to actually get from the respondents
The suitability of the data for the machine learning exercise.
Develop and Deploy the LSTM Model – We shall then develop the LSTM model and deploy it on the mobile device to examine the practicality of our proposed approach to BP prediction.
Over 5% of the world’s population (466 million people) has disabling hearing loss. 4 million are children [1]. They can be hard of hearing or deaf. Hard of hearing people usually communicate through spoken language and can benefit from assistive devices like cochlear implants. Deaf people mostly have profound hearing loss, which implies very little or no hearing.
Abdelhak Mahmoudi is Associate Professor at the Department of Computer Science of Ecole Normale Supérieure (ENS-Rabat) of Mohammed V University
Salma EL ANIGRI is a Ph.D. student at Laboratoire d’Informatique, Mathématique Appliquée, Intelligence Artificielle et reconnaissance de Formes (LIMIARF)
Abdessamad EZZOU is a Ph.D. student at Laboratoire d’Informatique, Mathématique Appliquée, Intelligence Artificielle et reconnaissance de Formes (LIMIARF)
Mohamed El-kaddoury is a Ph.D. student in machine learning at Laboratoire d’Informatique, Mathématique Appliquée, Intelligence Artificielle et reconnaissance de Formes (LIMIARF)
Younes Choubik is a PhD student at Laboratoire d’Informatique, Mathématique Appliquée, Intelligence Artificielle et reconnaissance de Formes (LIMIARF)
The main impact of deaf people is on the individual’s ability to communicate with others in addition to the emotional feelings of loneliness and isolation in society. Consequently, they cannot equally access public services, mostly education and health and have no equal rights in participating in an active and democratic life. This leads to a negative impact in their lives and the lives of the people surrounding them.
Over the world, deaf people use sign language to interact in their community. Hand shapes, lip patterns, and facial expressions are used to express emotions and to deliver meanings. Sign languages are full-fledged natural languages with their own grammar and lexicon. However, they are not universal although they have striking similarities. Sign language can be represented by a form of annotation called Gloss. Each sign is represented by a gloss.
In Morocco, deaf children receive very little education assistance. For many years, they were learning the local variety of sign language from Arabic, French, and American Sign Languages [2]. In April 2019, the government standardized the Moroccan Sign Language (MSL) and initiated programs to support the education of deaf children [3]. However, the involved teachers are mostly hearing, have limited command of MSL and lack resources and tools to teach deaf to learn from written or spoken text. Schools recruit interpreters to help the student understand what is being taught and said in class. Otherwise, teachers use graphics and captioned videos to learn the mappings to signs, but lack tools that translate written or spoken words and concepts into signs.
Around the world, many efforts by different countries have been done to create Machine translations systems from their Language into Sign language. At Laboratoire d’Informatique de Mathématique Appliquée d’Intelligence Artificielle et de Reconnaissance des Formes (LIMIARF https://limiarf.github.io/www/) of Faculty of Sciences of Mohammed V University in Rabat, the Deep Learning Team (DLT) proposed the development of an Arabic Speech-to-MSL translator. The translation could be divided into two big parts, the speech-to-text part and the text-to-MSL part. Our main focus in this current work is to perform Text-to-MSL translation.
This project brings up young researchers, developers and designers. As a team, we conducted many reviews of research papers about language translation to glosses and sign languages in general and for Modern Standard Arabic in particular. We collected data of Moroccan Sign language from governmental, non-governmental sources and form the web. The young researchers also conducted some research on a new way to translate Arabic to a sign gloss. In parallel, young developers was creating the mobile application and the designers designing and rigging the animation avatar. In the following we detail these tasks.
Research reviews
[4] built a translation system ATLASLang that can generate real-time statements via a signing avatar. The system is a machine translation system from Arabic text to the Arabic sign language. It performs a morpho-syntactic analysis of the text in the input and converts it to a video sequence sentence played by a human avatar. They animate the translated sentence using a database of 200 words in gif format taken from a Moroccan dictionary. If the input sentence exists in the database, they apply the example-based approach (corresponding translation), otherwise the rule-based approach is used by analyzing each word of the given sentence in the aim of generating the corresponding sentence.
[5] decided to keep the same model above changing the technique used in the generation step. Instead of the rules, they have used a neural network and their proper encoder-decoder model. They analyse the Arabic sentence and extract some characteristics from each word like stem, root, type, gender etc. These features are encapsulated with the word in an object then transformed into a context vector Vc which will be the input to the feed-forward back-propagation neural network. The neural network generates a binary vector, this vector is decoded to produce a target sentence.
[6] This paper describes a suitable sign translator system that can be used for Arabic hearing impaired and any Arabic Sign Language (ArSL) users as well.The translation tasks were formulated to generate transformational scripts by using bilingual corpus/dictionary (text to sign). They used an architecture with three blocks: First block: recognize the broadcast stream and translate it into a stream of Arabic written script.in which; it further converts such stream into animation by the virtual signer. Therefore, the proposed solution covers the general communication aspects required for a normal conversation between an ArSL user and Arabic speaking non-users. The second block: converts the Arabic script text into a stream of Arabic signs by utilising the rich module of semantic interpretation, language model and supported dictionary of signs. From the language model they use word type, tense, number, and gender in addition to the semantic features for subject, and object will be scripted to the Signer (3D avatar). Third block: works to reduce the semantic descriptors produced by the Arabic text stream into simplified from <Subject, Verb, Object> by helping of ontological signer concept to generalize some terminologies. The proposed tasks employ two phases: training and generative phases. The two phases are supported by the bilingual dictionary/corpus; BC = {(DS, DT)}; and the generative phase produces a set of words (WT) for each source word WS.
[7] This paper presents DeepASL, a transformative deep learning-based sign language translation technology that enables non-intrusive ASL translation at both word and sentence levels.ASL is a complete and complex language that mainly employs signs made by moving the hands. Each individual sign is characterized by three key sources of information: hand shape, hand movement and relative location of two hands. They use Leap Motion as their sensing modality to capture ASL signs.DeepASL achieves an average 94.5% word-level translation accuracy and an average 8.2% word error rate on translating unseen ASL sentences.
[8] Achraf and Jemni, introduced a Statistical Sign Language Machine Translation approach from English written text to American Sign Language Gloss. First, a parallel corpus is provided, which is a simple file that contains a pair of sentences in English and ASL gloss annotation. Then a word alignment phase is done using statistical models such as IBM Model 1, 2, 3, improved using a string-matching algorithm for mapping each English word into its corresponding word in ASL Gloss annotation. Then a Statistical Machine translation Decoder is used to determine the best translation with the highest probability using a phrase-based model. Regarding that Arabic deaf community represent 25% from the deaf community around the world, and while the Arabic language is a low-resource language. Many ArSL translation systems were introduced.
[9] Aouiti and Jemni, proposed a translation system called ArabSTS (Arabic Sign Language Translation System) that aims to translate Arabic text to Arabic Sign Language. This system takes MSA or EGY text as input, then a morphological analysis is conducted using the MADAMIRA tool, next, the output directed to the SVM classifier to determine the correct analysis for each word. Later, the result is written in an XML file and given to an Arabic gloss annotation system. The proposed gloss annotation system provides a global text representation that covers a lot of features (such as grammatical and morphological rules, hand-shape, sign location, facial expression, and movement) to cover the maximum of relevant information for the translation step. This system is based on the Qatari Sign Language rules, each gloss is represented by an Arabic word that identifies one Arabic Sign. Then, The XML file contains all the necessary information to create a final Arab Gloss representation or each word, it is divided into two sections. In the first part, each word is assigned to several fields (id, genre, num, function, indication), and the second part gives the final form of the sentence ready to be translated. By the end of the system, the translated sentence will be animated into Arabic Sign Language by an avatar.
[10] Luqman and Mahmoud, build a translation system from Arabic text into ArSL based on rules. The proposed work introduces a textual writing system and a gloss system for ArSL transcription. This approach is semantic rule-based. The architecture of the system contains three stages: Morphological analysis, syntactic analysis, and ArSL generation. The Morphological analysis is done by the MADAMIRA tool while the syntactic analysis is performed using the CamelParser tool and the result for this step will be a syntax tree. For generating the ArSL Gloss annotations, the phrases and words of the sentence are lexically transformed into its ArSL equivalents using the ArSL dictionary. After the lexical transformation, the rule transformation is applied. Those rules are built based on differences between Arabic and ArSL, that maps Arabic to ArSL in three levels: word, phrase, and sentence. Then the final representation will be given in the form of ArSL gloss annotation and a sequence of GIF images.
[11] Automatic speech recognition is the area of research concerning the enablement of machines to accept vocal input from humans and interpreting it with the highest probability of correctness. Arabic is one of the most spoken languages and least highlighted in terms of speech recognition. The Arabic language has three types: classical, modern, and dialectal. Classical Arabic is the language Quran. Modern Standard Arabic (MSA) is based on classical Arabic but with dropping some aspects like diacritics. It is mainly used in modern books, education, and news. Dialectal Arabic has multiple regional forms and is used for daily spoken communication in non-formal settings. With the advent of social media, dialectal Arabic is also written. Those forms of the language result in lexical, morphological and grammatical differences resulting in the hardness of developing one Arabic NLP application to process data from different varieties. Also there are different types of problem recognition but we will focus on continuous speech. Continuous speech recognizers allow the user to speak almost naturally. Due to the utterance boundaries, it uses a special method, which is why it is considered as one of the most difficult systems to create.
[12] An AASR system was developed with a 1,200-h speech corpus. The authors modeled a different DNN topologies including: Feed-forward, Convolutional, Time-Delay, Recurrent Long Short-Term Memory (LSTM), Highway LSTM (H-LSTM) and Grid LSTM (GLSTM). The best performance was from a combination of the top two hypotheses from the sequence trained GLSTM models with 18.3% WER.
[13] A comparison for some of the state-of-the-art speech recognition techniques was shown. The authors applied those techniques only to a limited Arabic broadcast news dataset. The different approaches were all trained with a 50-h of transcription audio from a news channel “Al-jazirah”. The best performance obtained was the hybrid DNN/HMM approach with the MPE (Minimum Phone Error) criterion used in training the DNN sequentially, and achieved 25.78% WER.
[14] Speech recognition using deep-learning is a huge task that its success depends on the availability of a large repository of a training dataset. The availability of open-source deep-learning enabled frameworks and Application Programming Interfaces (API) would boost the development and research of AASR. There are multiple services and frameworks that provide developers with powerful deep-learning abilities for speech recognition. One of the marked applications is Cloud Speech-to-Text service from Google which uses a deep-learning neural network algorithm to convert Arabic speech or audio file to text. Cloud Speech-to-Text service allows for its translator system to directly accept the spoken word to be converted to text then translated. The service offers an API for developers with multiple recognition features.
[15] Another service is Microsoft Speech API from Microsoft. This service helps developers to create speech recognition systems using deep neural networks. IBM cloud provides Watson service API for speech to text recognition support modern standard Arabic language.
Data collection
Because of the lack of data resources about the Arabic sign language. We dedicated a lot of energy to collect our own datasets. For this end, we relied on the available data from some official [16] and non-official sources [17, 18, 19] and collected, until now, more than 100 signs. The dataset is composed of videos and a .json file describing some meta data of the video and the corresponding word such as the category and the length of the video.
Data collection
Published Research
Our long abstract paper [20] intitled ‘Towards A Sign Language Gloss Representation Of Modern Standard Arabic’ was accepted for presentation at the Africa NLP workshop of the 8th International Conference on Learning Representations (ICLR 2020) in April 26th in Addis Ababa Ethiopia. In this paper we were interested in the first stage of the translation from Modern Standard Arabic to sign language animation that is generating a sign gloss representation. We identified a set of rules mandatory for the sign language animation stage and performed the generation taking into account the pre-processing proven to have significant effects on the translation systems. The presented results are promising but far from well satisfying all the mandatory rules.
Mobile Application
The application is developed with Ionic framework which is a free and open source mobile UI toolkit for developing cross-platform apps for native iOS, Android, and the web : all from a single codebase. The application is composed of three main modules: the speech to text module, the text to gloss module and finally the gloss to sign animation module.
In the speech–to–text module, the user can choose between the Modern Standard Arabic language and the French language. The user can long-press on the microphone and speak or type a text message. The voice message will be transcribed to a text message using the google cloud API services. In the text-to-gloss module, the transcribed or typed text message is transcribed to a gloss. This module is not implemented yet. The results from our published paper are currently under test to be adopted. Finally, in the the gloss–to-sign animation module, at first attempts, we tried to use existing avatars like ‘Vincent character’ [ref], a popular avatar with high-quality rigged character freely available on Blender Cloud. We started to animate Vincent character using Blender before we figured out that the size of generated animation is very large due to the character’s high resolution. Therefore, in order to be able to animate the character with our mobile application, 3D designers joined our team and created a small size avatar named ‘Samia’. The designers recommend using Autodesk 3ds Max instead of Blender initially adopted. 3ds Max is designed on a modular architecture, compatible with multiple plugins and scripts written in a proprietary Maxscript language. In future work, we will animate ‘Samia’ using Unity Engine compatible with our Mobile App.
[4] Brour, Mourad & Benabbou, Abderrahim. (2019). ATLASLang MTS 1: Arabic Text Language into Arabic Sign Language Machine Translation System. Procedia Computer Science. 148. 236-245. 10.1016/j.procs.2019.01.066.
[5] Brour, Mourad & Benabbou, Abderrahim. (2019). ATLASLang NMT: Arabic text language into Arabic sign language neural machine translation. Journal of King Saud University – Computer and Information Sciences. 10.1016/j.jksuci.2019.07.006.
[7] Omar H. Al-Barahamtoshy, Hassanin M. Al-Barhamtoshy. (2017). ”Arabic Text-to-Sign (ArTTS) Model from Automatic SR System”. 3rd International Conference on Arabic Computational Linguistics, ACLing 2017, Dubai, United Arab Emirates. https://doi.org/10.1016/j.procs.2017.10.122
[8] A. Othman and M. Jemni, “Statistical Sign Language Machine Translation: from English written text to American Sign Language Gloss,” vol. 8, no. 5, p. 9, 2011.
[9] N. Aouiti and M. Jemni, “Translation System from Arabic Text to Arabic Sign Language,” JAIS, vol. 3, no. 2, pp. 57–70, Dec. 2018, doi:33633/jais.v3i2.2041.
[10] H. Luqman and S. A. Mahmoud, “Automatic translation of Arabic text-to-Arabic sign language,” Universal Access in the Information Society, vol. 18, pp. 939–951, 2018, doi:1007/s10209-018-0622-8.
[11] Algihab, W., Alawwad, N., Aldawish, A., & AlHumoud, S. (2019). Arabic Speech Recognition with Deep Learning: A Review. Lecture Notes in Computer Science, 15–31. doi:10.1007/978-3-030-21902-4_2
[12] AlHanai, T., Hsu, W.-N., Glass, J.: Development of the MIT ASR system for the 2016 Arabic multi-genre broadcast challenge. In: 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, pp. 299–304 (2016)
[13] Cardinal, P., et al.: Recent advances in ASR applied to an Arabic transcription system for AlJazeera, p. 5.
[14] Khurana, S., Ali, A.: QCRI advanced transcription system (QATS) for the Arabic multidialect broadcast media recognition: MGB-2 challenge. In: 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, pp. 292–298 (2016)
[15] Graciarena, M., Kajarekar, S., Stolcke, A., Shriberg, E.: Noise robust speaker identification for spontaneous Arabic speech. In: 2007 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2007, Honolulu, HI, pp. IV-245–IV-248 (2007)
Swahili(also known as Kiswahili) is one of the most spoken languages in Africa. It is spoken by 100–150 million people across East Africa. Swahili is popularly used as a second language by people across the African continent and taught in schools and universities. Given its presence within the continent and outside, learning Swahili is a popular choice for many language enthusiasts. In Tanzania, it is one of two national languages (the other is English).
News in Swahili is an important part of the media sphere in Tanzania. News contributes to education, technology, and the economic growth of a country, and news in local languages plays an important cultural role in many Africa countries. In the modern age, African languages in news and other spheres are at risk of being lost as English becomes the dominant language in online spaces.
Objective
Swahili open-source text datasets are not often available in Tanzania that results in being left behind in the creation of NLP technologies to solve African challenges.
The goal of this project is to build an open-source text dataset in the Swahili language focused on News articles. I mainly focus on collecting news at different categories such as Local, International, Business or Financial, health, sports, and entertainment. The dataset will be open-source, and NLP practitioners will be able to access the dataset and learn from it.
Implementation
I was able to implement the following phases of the project in order to achieve the objective of the project.
Collect website with Swahili news: The first phase of the project is to find and collect different websites that provide news in the Swahili language. I was able to find some websites provide news in Swahili only and others in different languages including Swahili.
Understand policy and copyright: In this phase of the project, I mainly focus on understanding their policies and copyrights for each website on what I can do and what I can not do.AI4D helped me to understand this by providing a Data Protection Guidelines to consider for data collection and data mining.
Understand the structure of the news website: Each news website was developed by different web technologies such as PHP, Python, WordPress, Django, javascript e.t.c. The main task is to analyze website source code by using a web browser tool (view page source). I looked at different HTML tags to find news titles, categories, and links to access the content of the particular title.
Data Collection: news articles were collected by using different tools and programming languages. These tools are as follow: Python programming language, Jupyter notebook, Python open-source packages (NumPy, pandas, and BeautifulSoup). The collected news articles were saved in a CSV file (contains the content and the category of particular news e.g sports)
Analyze and Cleanin: The collected news articles were analyzed and cleaned to remove irrelevant information such as HTML tags and symbols that were collected during the scrapping process.
Results
At the end of this project, I was able to achieve the following milestones
Collecting and organizing a total of 40,331 news (with a total number of words = 12,488,239).
I have collected news from different six categories which are local,International,business,health,sports and entertainment
The main challenge is the imbalance of collected news from different categories. For example we have few news focus on international, business and health news.
I would like to extend my thanks to the AI4D(Artificial Intelligence for Development Africa) team and other partners in this AI4D-language dataset fellowship for their support and guidance throughout the project. Also, I have learned a lot from my fellow researchers across Africa who participated in this program to develop datasets in our Africa languages.
In this work, we propose to create a Wolof text to speech dataset. Text To Speech(TTS) dataset is composed of pairs of text and audio, where it’s text is the transcription of the associated audio. But before we deep dive in the process of collecting the dataset, let’s take a look at some interesting facts about Wolof language and why it is important to build such dataset.
Wolof /ˈwoʊlɒf/[4] is a language of Senegal, the Gambia and Mauritania, and the native language of the Wolof people. Like the neighbouring languages Serer and Fula, it belongs to the Senegambian branch of the Niger–Congo language family. Unlike most other languages of the Niger-Congo family, Wolof is not a tonal language.[1]
Wolof is spoken by more than 10 million people and about 40 percent (approximately 5 million people) of Senegal’s population speak Wolof as their native language. Increased mobility, and especially the growth of the capital Dakar, created the need for a common language.
Today, an additional 40 percent of the population speak Wolof as a second or acquired language. In the whole region from Dakar to Saint-Louis, and also west and southwest of Kaolack, Wolof is spoken by the vast majority of the people.
Typically when various ethnic groups in Senegal come together in cities and towns, they speak Wolof. It is therefore spoken in almost every regional and departmental capital in Senegal.[1]
Goal and benefits
Our goal here is to help researchers and companies to have a dataset that they can use to experiment and build automatic systems that can convert text to audio. This type of system can help people with reading problems (e.g blind or illiterate people) to get information and interact with other people or even new technologies(e.g web and mobile applications). There is also the fact that Wolof is not written correctly by most Wolof natifs and non natif, so it becomes difficult for them to read Wolof text, but with a TTS system they could easily be able to understand Wolof text and also learn how Wolof should be written in the process.
Text data collection and preparation
The text collection is the phase of creating clean and representative text that can be used to do the recordings.
Sources: Unlike popular languages, such as english or french, Wolof texts are very scarce on the Internet and in general in digital form, so we had to make more effort just to get the raw text data.
The text used to build this dataset is collected from different sources, such as Wolof website news(sabaal and dekufi), wikipedia and many many texts provided by the Wolof expert in our team.
Cleaning: The cleaning of the text was the most challenging and time consuming task of this work. We had to remove some non Wolof sentences, non used symbols or words, long sentences or paragraphs. There was also manual cleaning of the data.
We also developed with the help of our Wolof expert an algorithm to convert Wolof text to Wolof phonemes. This part is crucial here, because we needed to verify if the text corpus covers correctly the Wolof phonemes, because if phonemes are not covered correctly, the resulting TTS system will have difficulties converting some phonemes to their corresponding sound. After some iteration, we were able to choose sentences that cover all Wolof phonemes with a good distribution with respect to phonemes frequencies .
Where are we: the collection of the text is complete with more than 30 000 sentences cleaned and ready for recording.
Audio data collection
The audio collection is the phase of creating recordings that correspond to the already cleaned text.
The human part: The audio collection is done by two actors, a male and a female voice. Each one needs to record at least 20 000 out of the 30 000 cleaned sentences. We have had some issues on starting the recording due to the time of text cleaning but, we also had some delay with respect to having the microphone and the material resources needed to do the recording. The other problem we had here was building the Web platform that actors use to do the recording, which we will talk about in the next section.
The platform for recording: We forked and modified open source project Common Voice[2], which is a project from Mozilla to help our actors to easily due the recording using just their internet browser. Data is collected and automatically sent to an S3 bucket after each 5 recordings.
Where are we: We had a big delay on the collection of the recordings (the recording started just three weeks ago), as writing this article(2020/10/20), we have collected 4000 out of the 40 000 recordings. But we hope that the recording rate will be higher after the actors are more used to the process. We are expecting to collect at least 1400 recordings per week from the two actors.
Also after the recording is done, we will verify and clean the audio data set, for example, trim silences, duration check, and so on. We will also build à baseline model with this dataset and make it available to the community.
Conclusion
We are really grateful to AI4D for giving us the possibility and the means to build and collect a Wolof TTS dataset and we hope that this kind of initiative will be more frequent to help create more and more dataset for our local languages so that new system and models can be built with them and so increase accessibility to new technologies but also help more people to have access to information in their own language.
The aim of our project is to investigate the technological feasibility of deploying Unmanned Ground Vehicles for automated wildlife patrol, as well as performing a preliminary analysis of other metadata collected from officials at a national park in Kenya. To this end, we seek to collect and publish a dataset of driving data across national park trails in Kenya, the first of its kind, and use deep learning to predict steering wheel angle when driving on these trails.
Khushal Brahmbhatt, Deep Learning and Computer Vision researcher, Autonomous Vehicles
Ronald Ojino Co-researcher (Autonomous Driving Research)/ PhD student (University of Dar es Salaam)/Lecturer – Cooperative University of Kenya
Setting up the data acquisition system
The data collection required a vehicle mounted with a camera to be driven across national park trails while recording the trail video as well as key driving signals such as steering wheel angle, speed and brake and accelerator pedal positions. We began design, installation and configuration of the data collection system in November and December 2019.
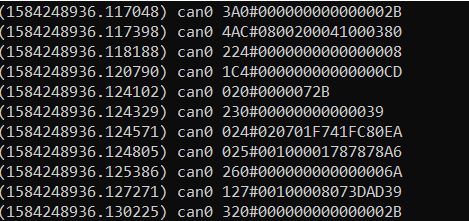
The first idea was to procure and attach sensors to the vehicle to obtain these driving signals. But upon further research, it was discovered that most of these driving signals can be read from the CAN bus which is exposed on the OBD-II (On-Board Diagnostics) port on most vehicles manufactured after 2008.
This information however is grouped and encoded within different parameter ids, and it requires reverse engineering to identify each of these driving parameters which is significantly time consuming, an activity that would take months by itself.
Furthermore, not all of the driving signals would be exposed on the CAN bus. The parameters exposed on the bus vary between vehicle manufacturers and models, and so does the encoding. After failing to understand the data read from the CAN bus of our personal vehicles, we decided to find a vehicle model which had already been reverse-engineered.
We were able to identify [1] and procure a Toyota Prius 2012 for the data collection, from which we could read the steering wheel angle, steering wheel torque, vehicle speed, individual wheel speeds and brake and accelerator pedal positions. We used a Raspberry Pi 3 microcomputer with the PiCan hat to read and log the driving signals.
Encoded driving data seen on the vehicle’s CAN bus
In order to create the dataset for training and testing the learning algorithm, each data sample would have to contain a video frame matched to the corresponding driving signals at that instance. That means all the video frames, as well as the driving signals, have to be timestamped.
The driving signals are automatically timestamped during logging on the Raspberry Pi, but most cameras don’t timestamp the individual frames. Further, the internal clock of the camera would not be in sync with that of the RPi’s, and would cause the video frames and driving signals to also be out of sync when creating the data samples.
That means a camera that could interface to the computer as a webcam would be needed, so each frame can be read and timestamped before being written to the video file. Driving on rough national park trails would also induce a lot of vibrations and require a camera with good stabilization. These were some of the challenges in selecting a camera for recording the driving video.
We settled on the Apeman A80 action camera which has gyro stabilization, HD video recording and can also function as a webcam. OpenCV was used to read and record timestamped video to the computer.
Initially, we tried to connect the camera to the Raspberry Pi itself. But the RPi is a low-powered microcomputer. There was significant lag in recording and could not write the video higher than a frame rate of 8fps. We therefore decided to use a laptop which could comfortably record HD
video at 30fps to connect to the camera, and the RPi for only logging the driving signals from the vehicle’s CAN bus.
This however presented a different challenge of being limited by the laptop battery. While the RPi can be charged using a portable power bank or directly from the car’s charging port, the laptop cannot. That meant significantly shorter data collection runs. We could only drive around continuously for 2 hours before we had to return to charge the laptop which took another 2 hours.
This forced revising down our overall data collection projections from 50 hours to 20 hours, of which 25 hours which was to be on the national park trails was revised down to 10 hours, and the other 10 hours on a mixture of tarmac roads and other rural dirt roads.
There was also extensive testing of different video encoding methods to determine the best filesize versus quality tradeoff, as well as data collection code optimization to ensure minimum lag during the data logging.
Data collection
We began the data collection in January 2020 on tarmac and rural dirt roads. The idea behind this was to train the algorithm on a simpler dataset and then use transfer learning for better faster results on the national park trails. The data was collected at various times of the day: early in the morning, noon and late in the evening in order to get a varied dataset in different lighting conditions.
While we were able to smoothly collect the data on tarmac roads, driving over the rural dirt roads proved impossible as they were marked with potholes. Not only was it challenging to drive a low-body vehicle over the rough terrain, but the constant maneuvers made to go around the potholes meant that most of that data would be unusable as it would present a different challenge altogether in training.
The challenge of driving a low-body vehicle on dirt roads also limited our choices of national parks, as we had to carefully select ones with smooth driving trails. Our plan to collect data from the Maasai Mara National Reserve had to be abandoned due to the bad road conditions there, and we opted to collect data from Nairobi National Park (8 hrs) and Ruma National Park (2.5 hrs) instead. Even these however were not without their setbacks involving a flat tire and bumper damage.
Sample video frames from Nairobi National Park (left, center) and Ruma National Park (right)
Sample video frames from Nairobi National Park (left, center) and Ruma National Park (right)
Sample video frames from Nairobi National Park (left, center) and Ruma National Park (right)
Another challenge faced in the parks was internet connectivity. While a stable internet connection was not needed for the data collection which was done offline, a connection to the internet was needed when starting up the Raspberry Pi to allow it to initialize the correct datetime value.
This is because the RPi microcomputer does not have an internal clock. That means unless it has a connection to the internet, it will resume the clock from the last saved time before it was shut down, hence ending up showing the wrong time. That resulted in incorrect timestamps on the logged driving data that could not be matched to the video timestamps.
This was observed while analyzing the driving data logs from one of the runs at Ruma National Park. Luckily, internet connectivity was regained towards the end of the run and the rest of the timestamps could be calculated correctly using the message baud rates.
Other minor issues faced in obtaining good quality data involved keeping the windshield clean while driving on dusty park trails where one is not allowed to alight from the vehicle, and securely mounting the camera inside the vehicle while driving over rough terrain.
Dataset preparation and Training
A significant portion of the data collected included driving around potholes, overtaking, stopping, U-turns etc. which would not be useful for predicting the steering wheel angle within the scope of this study. All these segments had to be visually identified and removed before
preparing the dataset.
Initially, we proposed to use a simple Convolutional Neural Network (CNN) model for training as in [2], where the steering wheel angle is predicted independently on each video frame as the input. However, the steering angle is also largely dependent on the speed of the vehicle. Driving
is also a stateful process, where the current steering wheel angle is also dependent on the previous wheel position.
We therefore investigated the use of a more sophisticated temporal CNN model as in [3] using recurrent units such as LSTM and Conv-LSTM that could give more promising results. The above model however is very computationally expensive and would require a cluster of very expensive GPUs and still take days to train.
Using this model proved impossible to achieve within the given timeline and budget. We therefore decided to continue with our initial proposal using a static CNN model [2].
Currently we are in the process of building the dataset and learning model for the project. We are also working on preparing a preliminary analysis on the feasibility of automated wildlife patrol [4] based on other metadata collected from park officials.
We are grateful for the immense support that we always get from our mentor Billy Okal who in spite of his busy schedule, gets the time to set up calls whenever we need to consult and always comes up with great ideas that address most of our concerns.
References
[1] C. Miller and C. Valasek, Adventures in Automotive Networks and Control Units, IOActive
Inc., 2014, pp. 92-97.
[2] M. Bojarski et al., End to end learning for self-driving cars, 2016, arXiv:1604.07316.
[3] L. Chi and Y. Mu, Deep steering: Learning end-to-end driving model from spatial and
temporal visual cues, 2017, arXiv:1708.03798.
[4] L. Aksoy et al., Operational Feasibility Study of Autonomous Vehicles, Turkey International
Logistics and Supply Chain Congress, 2016.
Amelia Taylor, University of Malawi | UNIMA · Information Technology and Computing
Here is an example of a case for which a PDF is available on MalawiLii. Here is an example of a case for which only a scanned image of a pdf is available. We used OCR for more than 90% of data to extract the text for our corpus (see below a description of our corpus).
Please open these files to familiarise yourself with the content of a court criminal judgment. What kind of information we want to extract? For each case we wanted:
Name of the Case
Number of the Case
Year in which the case was filled
Year in which the judgment was given, Court which issued the judgment
Names of Judges
Names of parties involved (appellants and respondents, but you can take this further and extract names of principal witnesses, and names of victims)
References to other Cases
Referencesto Laws/Statues and Codes, and,
Legal keywords which can help us classify the cases according to the ICCS classification.
This project has taught us so much about working with text, preparing data for a corpus, exchange formats for the corpus data, analysing the corpus using lexical tools, and machine learning algorithms for annotating and extracting information from legal text.
Along the way we experimented also with batch OCR processing and different annotation formats such as IOB tagging[1], and the XML TEI[2] standard for sharing and storing the corpus data, but also with the view of using these annotations in sequence-labelling algorithms.
Each has advantages and disadvantages, the IOB tagging does not allow nesting (or multiple labelling for the same element), while an XML notation would allow this but it is more challenging to use in algorithms. We also learned how to build a corpus, and experimented with existing lexical tools for analysing this corpus and comparing it to other legal corpora.
We learned how to use POS annotations and contextual regular expressions to extract some of our annotations for laws and case citations and we generated more than 3000 different annotations. Another interesting thing we learned is that preparing annotated training data is not easy, for example, most algorithms require training examples to be of the same size and the training set needs to be a good representation of the data.
We also experimented with the classification algorithms and topics detection using skitlearn, spacy, weka and mathlab. The hardest task was to prepare the data in the right format and to anticipate how this data will lead to the outputs we saw. We felt that time spent in organising and annotating well is not lost but will result in gains in the second stage of the project when we focus on algorithms.
Most algorithms split the text into tokens, and for us, multi-word tokens (or sequences) are those we want to find and annotate. This means a focus on sequence-labelling algorithms. The added complications which are peculiar to legal text is that most of our key terms belong logically to more than one label, and the context of a term can span multiple chunks (e.g., sentences).
When using LDA (Latent Dirichlet Association) to detect topics in our judgments, it became clear to us that one needs to use a somehow ‘sumarised’ version in which we collapse sequences of words into their annotations (this is because LDA uses term frequency-based measure of keyword relevance, whereas in our text the most relevant words may appear much less frequently than others).
Our work has highlighted to us the benefits and importance of multi-disciplinary cooperation. Legal text has its peculiarities and complexities so having an expert lawyer in the team really helped!
Finding references to laws and cases is made slightly more complicated because of the variety in which these references may appear or because of the use of “hereinafter”. Legal text makes use of “hereinafter”[3], e.g., Mwase Banda (“hereinafter” referred to as the deceased). But this can also happen for references to laws or cases as the following example shows:
Section 346 (3) of the Criminal Procedure and Evidence Code Cap 8:01 (hereinafter called “the Code”) which Wesbon J was faced with in the case of DPP V Shire Trading CO. Ltd (supra) is different from the wording of Section 346 (3) of the Code as it stands now.
Compare extracting the reference to law from “Section 151(1) of the Criminal Procedure and Evidence Code” to extracting from “Our own Criminal Procedure and Evidence Code lends support to this practice in Sections 128(d) and (f)”. We have identified a reasonably large number of different references to laws and cases used in our text! The situation is very similar for case citations. Consider the following variants:
Republic v Shautti , Confirmation case No. 175 of 1975 (unreported)
Republic v Phiri [ 1997] 2 MLR 68
Republic v Francis Kotamu , High Court PR Confirmation case no. 180 of 2012 ( unreported )
Woolmington v DPP [1935] A.C. 462
Chiwaya v Republic 4 ALR Mal. 64
Republic v Hara 16 (2) MLR 725
Republic v Bitoni Allan and Latifi Faiti
Something for you to Do Practically! To play with some annotations and appreciate the diversity in formats, and at the same time the huge savings that a semi-automatic annotation can bring, we have set up a doccano platform for you: you log in here using the user guest and password Gu3st#20.
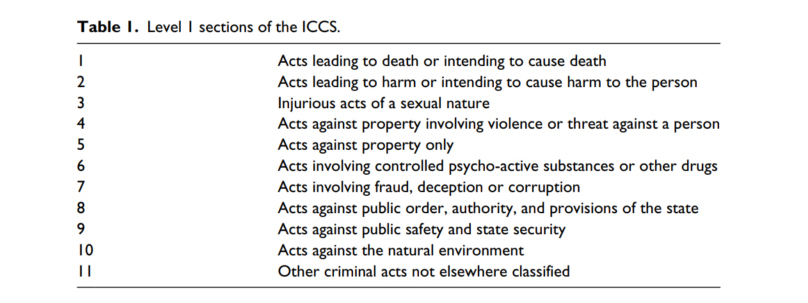
Annotating with keywords for the purposes of the ICCS classification proved to be even harder. The International Classification of Crime for Statistical Purposes (ICCS)[4] and it is a classification of crimes as defined in the national legislations and comes on several levels each with varying degrees of the specification. We considered mainly the Level 1 and we wanted to classify our judgments according to the 11 types in Level 1 as shown in the Table.
Table 1: Level 1 sections of the ICCS
We discovered that this task of classification according to Level 1 requires a lot of work and it is of a significant complexity (and the complexities only grow if we would consider the sublevels of the ICCS). First, the legal expert of our team manually classified all criminal cases of 2019 according to Level 1 ICCS and worked on a correspondence between the Penal Code and the ICCS classification. This is excellent.
We are in the process of extending this to mapping other Malawi laws, codes and statutes that are relevant to criminal cases into the ICCS. This in itself is a whole project on its own for the legal profession and requires processing a lot of text and making ‘parallel correspondences’! Such national correspondence tables are still work in progress in most countries and to our knowledge, our work is the first of such work for Malawi.
Looking at Level 1 of the ICCS meant we were kept very busy. Our research centred on hard and important questions. How to represent our text so that it can be processed efficiently? What kind of data labels are most useful for the ICCS classification? What type of annotations to use (IOB or an xml-based)? What algorithms to employ (Hidden Markov Models or Recurrent Neural Networks or Long Short Term Memory)? But most importantly, we focussed on how to prepare our annotated data to be used with these algorithms?
We need to be mindful that this is a fine classification because we have to distinguish between texts that are quite similar. For example, if we wanted to classify whether a judgment by the type of law it falls under, say whether it is either civil or criminal case, this would have been slightly easier because the keywords/vocabulary used in civil cases would be quite different than that used in criminal cases.
We want to distinguish between types of crimes, and the language used in our judgments is very similar. Within our data set there is the level of difficulty, e.g., theft and murder cases may be easier to differentiate, that is Type 1 and 7 from the table above, than, say, to differentiate between types 1 and 2.
We have the added complication that most text representation models which define the relevance of a keyword as given by its frequency (whether that is TF or TF-IDF) but in our text, a word may appear only once and still be the most significant word for the purpose of our classification. For example, a keyword that distinguishes between type 1 and type 2 murders is “malice aforethought” and this may only occur once in the text of the judgment.
To help with this situation, one can extract first the structure of the judgment and focus only on the part that deals with the sentence of the judge. Indeed, there is research that focuses only on extracting various segments of a judgment.
This may work in many cases because usually the sentence is summarised in one paragraph. But it does not work for all cases. This is so especially when the case history is long, the crime committed has several facets, or the case has several counts, e.g., the murder victim is an albino or a disabled person.
In such situations one needs a combined strategy which uses: (1) An good set of annotated text with meta-data described above; (2) the mapping of the Penal Code/ Laws/Statues relevant to the ICCS; (3) collocations of words/ or a thesaurus and (4) concordances to help us detect clusters and extract relevant portions of the judgments; (5) employing sequence modelling algorithms, e.g., HMM, recurrent neural networks, for annotation and classification.
In the first part of the project, we focussed on the tasks (1) – (4) and experimented to some extent with (5). What we wanted is to find a representation of our text based on all the information at (1) – (4) and attempt to use that in the algorithms we employ.
We have created a training set of over 2500 annotations for references to sections of the law and over 1000 annotations for references to other cases. We are still preparing these so that they are representative of the corpus and are good examples.
And finally but most importantly, while working on this AI4D project, it has brought me in contact with very clever people, whom I would have not otherwise met. We appreciate the support and guidance of the AI4D team!
[3] Hereinafter is a term that is used to refer to the subject already mentioned in the remaining part of a legal document. Hereinafter can also mean from this point on in the document.
[4] United Nations Economic Commission for Europe. Conference of European Statisticians. Report of the UNODC/UNECE Task Force on Crime Classification to the Conference of European Statisticians. 2011. Available: www.unodc.org/documents/data-andanalysis/statistics/crime/Report_crime_classification_2012.pdf>
This research focuses on enhancing Pharmacovigilance Systems using Natural Language Processing on Electronic Medical Records (EMR). Our major task was to develop an NLP model for extracting Adverse Drug Reaction(ADR) cases from EMR. The team was required to collect data from two hospitals, which are using EMR systems (i.e. University of Dodoma (UDOM) Hospital and Benjamin Mkapa (BM) Hospital). During data collection and analysis, we worked with health professionals from the two mentioned hospitals in Dodoma. We also used the public dataset from the MIMIC-III database. These datasets were presented in different formats, CSV for UDOM hospital and MIMIC III and PDF for BM hospital as shown on the attached file.
Team during an interview with Pharmacologist in BM hospital
In most cases, pharmacovigilance practices depend on analyzing clinical trials, biomedical writing, observational examinations, Electronic Health Records (EHRs), Spontaneous Reporting (SR) and social media (Harpaz et al., 2014). As to our context, we considered EMR to be more informative compared to other practices, as suggested by (Luo et al., 2017). We studied schemas of EMRs from the two hospitals. We collected inpatients’ data since outpatients’ would have given the incomplete patient history. Also, our health information systems are not integrated, which makes it difficult to track patients’ full history unless patients were admitted to a particular hospital for a while. From all the data sources used there was a pattern of information that we were looking for, and this included clinical history, prior patient history, symptoms developed, allergies/ ADRs discovered during medication and patient’s discharge summary.
Gloriana Monko
Steven Edward
Zephania Reuben
Waziri Shebogholo
Ibrahimu Mtandu
Much as we worked on UDOM and BM hospitals’ data, we encountered several challenges that made the team focus on MIMIC-III dataset while searching for an alternative way to our local data. Here were the challenges noted:
The reports had no clear identification of ADR cases.
In most cases, the doctor did not mention the reasons for changing a medicine on a particular patient which made it hard to understand whether the medication didn’t work well for a specific patient or any other reasons like adverse reaction.
The justification for ADR cases was vague
Mismatch of information between patients and doctors
The patients talk in a way that doctor can’t understand
There is a considerable gap between the health workers and regulatory authorities (They don’t know if they have to report for ADR cases)
The issue of ADR is so complex since there is a lot to take into account like Drug to Drug, Drug to food and Drug to herbal interactions.
There was no common/consistent reporting style among doctors
The language used to report is hard for a non-specialist to understand.
Some fields were left empty with no single information which led to incomplete medical history
The annotation process prolonged since we had one pharmacologist for the work.
After noticing all these challenges, the team carefully studied the MIMIC-III database to assess the availability of the data with ADR cases which would help to come up with the baseline model to the problem. We discovered that the NoteEvent table has enough information about the patient history with all clear indications of ADR cases and with no ADR see the text.
To start with, we were able to query 100,000 records from the database with many attributes, but we used a text column found in the NoteEvent table with the entire patient’s history including (patient’s prior history, medication, dosage, examination, changes noted during medications, symptoms etc.). We started the annotation of the first group by filtering the records to remain with the rows of interest. We used the following keywords in the search; adverse, reaction, adverse events, adverse reaction and reactions. We discovered that only 3446 rows contain words that guided the team in the labelling process. The records were then annotated with the labels 1 and 0 for ADR and non-ADR cases respectively, as indicated in the filtration notebook.
In analysing the data, we found that there were more non-ADR cases than ADR cases, in which non-ADR cases were 3199 and 228 ADR cases and 19 data rows not annotated. Due to high data imbalance, we reduced Non-ADR cases to 1000, and we applied sampling techniques (i.e upsampling ADR cases to 800) to at least balance the classes to minimize bias during modelling.
After annotation and simple analysis we used NLTK to apply the basic preprocessing techniques for text corpus as follows:-
Converting the corpus-raw sentences to lower cases which helps in other processing techniques like parsing.
Sentence tokenization, due to the text being in paragraphs, we applied sentence boundary detection to segment text to sentence level by identifying sentence starting point and endpoint.
Then we worked with regular contextual expressions to extract information of interest from the documents by removing some of the unnecessary characters and replacing some with easily understandable statements or characters as for professional guidelines.
We removed affixes in tokens which put words/tokens into their root form. Also, we removed common words(stopwords) and applied lemmatization to identify the correct part of speech(s) in the raw text. After data preprocessing, we used Term Frequency Inverse Document Frequency (TF-IDF) from scikit-learn to vectorize the corpus, which also gives the best exact keywords in the corpus.
In modelling to create a baseline model, we worked with classification algorithms using scikit-learn. We trained six different models which are Support Vector Machines, eXtreme Gradient Boosting, Adaptive Gradient Boosting , Decision Trees, Multilayer Perceptron and Random Forest and then we selected three (Support Vector Machine, Multilayer Perceptron and Random Forest )models which performed better on validation compared to other models for further model evaluation. We’ll also use the deep learning approach in the next phase of the project to produce more promising results for the model to be deployed and kept in practice. Here is the link to colab for data pre-processing and modelling.
From the UDOM database, we collected a total of 41,847 patient records in chunks of 16185, 18400, and 7262 from 2017 to 2019 respectively. The dataset has following attributes (Date, Admission number, Patient Age, Sex, Height(Kg), Allergy status, Examination, Registration ID, Patient History, Diagnosis, and Medication ), we downsized it to 12,708 records by removing missing columns and uninformative rows. We used regular contextual expressions to extract information of interest from the documents as for professional guidelines. The data cleaned and exchanged data formatting, analyzing and preparing data for machine learning was elaborated in this Colab link.
On the BM hospital, the PDF files extracted from EMS have patient records with the following information.
Discharge reports
Medical notes
Patients history
Lab notes
Health professionals on the respective hospitals manually annotated the labels for each document, and this task took most of our time in this phase of the project. We’re still collecting and interpreting more data from these hospitals.
The team organizes and extracts information from BM hospital PDF files by exchanging data formatting, analyzing and preparing data for machine learning. We experimented with OCR processing for PDF files to extract data, but we didn’t generate promising results as more information appeared to be missing. We therefore hard to programmatically remove content from individual files and align them to the corresponding professional provided labels.
The big lesson that we have learned up to now is that most of the data stored in our local systems are not informative. Policymakers must set standards to guide system developers during development and health practitioners when using the system.
Lastly but not least, we want to thank our stakeholders, mentors and funders for your involvement in our research activities. It is because of such a partnership we can be able to achieve our main goal.
So why have we decided to collect malaria datasets to assist in developing a solution in its diagnosis? First, Malaria remains one of the significant threats to public health and economic development in Africa. Globally, it is estimated that 216 million cases of malaria occurred in 2017, with Africa bearing the brunt of this burden [5*]. In Tanzania, malaria is the leading cause of morbidity and mortality, especially in children under 5 years and pregnant women. Malaria kills one child every 30 seconds, about 3000 children every day [4*]. Malaria is also the leading cause of outpatients, inpatients, and admissions of children less than five years of age at health facilities [5*].
Martha Shaka
Frederick Apina
Said H Said
Halidi Maneno
Nyamos Waigama
Imani Sulutya
Said Mmaka
Emilian Ngatunga
Simon Chaula
Second, the most common methods to test for malaria are microscopy and Rapid Diagnostic Tests (RDT) [1, 2]. RDTs are widely used, but their chief drawback is that they cannot count the number of parasites. The gold standard for the diagnosis of malaria is, therefore, microscopy. Evaluation of Giemsa-stained thick blood smears, when performed by expert microscopists, provides an accurate diagnosis of malaria [3].
Nonetheless, there are challenges to this method, it consumes a lot of time to perform one diagnosis, requires experienced technologists who are very few in developing countries, and manually looking at the sample via a microscope is a tedious and eye-straining process. We learned that although a microscopic diagnostic is a golden standard for malaria diagnosis, it is still not used in most of the private and public health centers. We realized that some of the lab technologists in health care are not competent in preparing staining reagents used in the diagnosis process. We had to create our own reagents and supply to them for the purpose of this research.
Artificial intelligence is transforming how health care is delivered across the world. This has been evident in pathology detection, surgery assistance and early detection of diseases such as breast cancer. However, these technologies often require significant amounts of quality data and in many developing countries, there is a shortage of this.
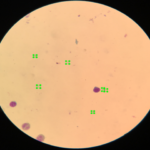
Taking images of stained blood smear
A sample of the annotated image( green box represent a plasmodium)
To address this deficiency, my team, composed of 6 computer scientists and 3 lab technologists, collected and annotated 10,000 images of a stained blood smear and developed an open-source annotation tool for the creation of a malaria dataset. We strongly believe the availability of more datasets and the annotation tool (for automating the labeling of the parasites in an image of stained blood smear) will improve the existing algorithms in malaria diagnosis and create a new benchmark.
In the collection of this dataset, we first sought and were granted ethical clearance from the University of Dodoma and Benjamin Mkapa Hospital’s research center. We have collected 50 blood smear samples for patients confirmed with malaria and 50 samples for negative confirmed cases. Each sample was stained by the lab technologist and 100 images were taken using iPhone 6S attached to a microscope. This led to having a total of 5000 images for the positive confirmed patients and 5000 imaged for the negative confirmed patient.
Through this work, we have had several opportunities including attending academic conferences and forming connections with other researchers such as Dr. Tom Neumark, a postdoctoral social anthropologist at the University of Oslo. Through our work, we also met Prof Delmiro Fernandes-Reyes, a professor of biomedical engineering. In a joint venture with Prof Delmiro Fernandes-Reyes, we submitted a proposal for the DIDA Stage 1 African Digital Pathology Artificial Intelligence Innovation Network (AfroDiPAI) at the end of November 2019.
We are also disseminating the results of our research. We have submitted an abstract (on the ongoing project) to two workshops (Practical Machine Learning in Developing Countries and Artificial Intelligence for Affordable Health) for the 2020 ICLR conference in Ethiopia, and it has been accepted to be presented as a poster. We were also delighted to get very constructive feedback from reviewers of the conference and look forward to incorporating them as we continue with the projects and final publication.
The next stage will be to start using our data and train deep learning models in the development of the open-source annotation tool. At the same time, together with the AI4D team, we are looking for the best approach to follow when releasing our open-source dataset in the medical field.
But our overall aim is to develop a final product of our mobile application that will assist lab technologist in Tanzania and beyond in the onerous work of diagnosis malaria. We have already met many of these technologists who are not only excited and eagerly awaiting this tool, but generously helped us as we have gone about developing it.
Links
[1] B.B. Andrade, A. Reis-Filho, A.M. Barros, S.M. Souza-Neto, L.L. Nogueira, K.F. Fukutani, E.P. Camargo, L.M.A. Camargo, A. Barral, A. Duarte, and M. Barral-Netto. Towards a precise test for malaria diagnosis in the Brazilian Amazon: comparison among field microscopy, a rapid diagnostic test, nested PCR, and a computational expert system based on artificial neural networks. Malaria Journal, 9:117, 2010.
[2]Maysa Mohamed Kamel, Samar Sayed Attia, Gomaa Desoky Emam, and Naglaa Abd El Khalek Al Sherbiny, “The Validity of Rapid Malaria Test and Microscopy in Detecting Malaria in a Preelimination Region of Egypt,” Scientifica, vol. 2016, Article ID 4048032, 5 pages, 2016. https://doi.org/10.1155/2016/4048032.
[3]Philip J. Rosenthal*, “How Do We Best Diagnose Malaria in Africa?”: https://doi.org/10.4269/ajtmh.2012.11-0619
A high yielding crop such as tomato with high economic returns can greatly increase smallholder farmers income when well managed. however, it is apparently constrained by the recent invasion of tomato pest Tuta absoluta that is devastating tomato yield. Look at tomato field situation in highly affected areas of arush [Arusha- mp4 video] and Morogoro regions.
Denis Pastory, team selfie – researcher and field assistant in the field.
To tackle this challenge, our work focus on an early detection and control measure initiatives in order to strengthen phytosanitary capacity and systems to help solve Tuta absoluta devastation using computer vision technique. It should be noted that Tuta absoluta control still rely on low-speed inefficient manual identification and a few on the support of limited number of agriculture extension officers.
Our initial works involved field work and in-house experiments to collect data in areas that are mostly affected by Tuta absoluta. We collected image data in Arusha and Morogoro regions of Tanzania.
Fig: Image of the P.I in one of in-house experiment site in Arusha.
As for any computer vision task, getting the right images for the task at hand is sometimes challenging. Regarding our use case, we had to generate our own image data. To accumulate enough data for model training, we have been collecting data since June 2018 and have had four (4) in-house experiments in the target areas. The whole data collection process is shown in this link.
The data collection process involved taking images of tomato inoculated with Tuta absoluta larvae for the first two (2) weeks of tomato growth since transplanting date. Images were taken for each plant on a daily basis. These images are RGB (Red, Green, Blue) photos of high and low resolutions. In order to acquire high resolution images, we used Canon EOS KISS X7 camera with a resolution of 5184 x 3456 pixels and we used mobile phone camera (set to low resolution).
For our previous first in-house experiment, we had encountered some challenge with the data collection process. The inoculated tomatoes were tagged with a red ribbon. Tagging species or target organisms is a common practice in fields such as entomology. We came to realize, that these tagged images couldn’t be included in the dataset for training our models and therefore had to exclude them from our model.
To meet our objectives, we worked on Convolution Neural Network (CNN) based model for a binary classification that could be able to identify tomatoes affected and not affected by Tuta Absoluta using the state-of-art of CNN architectures (VGG16, VGG19, ResNet50, InceptionV3). The results of this task were promising. Primary preprocessing tasks were limited to selecting the suitable images for training CNN model.
We are certain that the images we collected represented real images of small scale farmers’ fields. The images collected had more images with healthy tomato leaves than those inoculated with Tutaabsoluta which implies data imbalance. To reduce the bias our CNN model may encounter towards images with no Tuta absoluta samples, the number of samples per class were selected to create balanced classes during model training.
The main aim of the image data collection process was expected to cover the main tomato growing regions in Tanzania affected mostly by Tuta absoluta, though we ended up obtaining data from only two main areas. Our team is certain that the collected data can be a representative case covering Tanzania situation. Also we had to adopt to local agronomic practices of the two areas.
For instance, we collected data of the commonly grown tomato varieties. The in-house experiment was also carried out following the cropping calendar of the respected two regions. To cover the main two growing season in Arusha, we had to carry out three experiments and one experiment in Morogoro.
During CNN model training, following a typical early detection of pest or disease model approach, we managed to focus on identification of affected and none affected plants. We have successfully been able to develop this type of binary classification model to identify tomato affected by tuta and not affected by tuta.
We further, developed another multiclass classification, that would be used to classify tomato affected at mainly three levels of damage i.e. low, high and no damage. This approach gave us a much better sense of the original idea we had. The model results showed us that to meet an early detection system in determining damage at early stage, a typical quantification based model is much better than a binary classification model.
For instance, results of the multiclass model showed us that tomatoes that are highly damaged are easily identified compared to lowly damage tomato. In such case, it would be best to identify tomato damage at early stage i.e at low damage level in order to enhance early control measures for Tuta absoluta.
And this point, we are to redefine the model classification approach. Since the objective is early identification and if a simple classification model cannot perform such a task, this puts us at risk. With that in mind, we are further working on models that can identify Tuta absoluta mine density, a quantification method based on instance segmentation.