The network will be coordinated by Knowledge 4 All Foundation and IDRC in close collaboration with UNESCO Chair in AI.
Background
Artificial Intelligence (AI) has the potential to alter our world and to advance human development, with dramatic implications across every sector of society. According to PWC, AI could provide a 15.7 trillion-dollar boost to the world’s GDP by 2030 and is already bringing major advancements to the way we learn, conduct business and monitor our health.
There is a consensus that AI is changing our world, that it is here to stay and that it offers a vital commercial opportunity in every sector. However, the future of AI is uncertain, especially in Africa. While these technologies have accomplished impressive feats, including diagnosing disease and making self-driving cars a reality, other profound, and perhaps darker, implications have emerged.
Broad AI for Development intitiative
At the same time, the indiscriminate dissemination of AI applications could also exacerbate inequalities. As AI applications spread rapidly across sectors and around the globe, more research is required to better understand how AI applications impact human development.
To enhance the economic and social prospects of people in the Global South, it is critical to support knowledge, skills development, and the institutions to responsibly implement and govern these technologies.
To this end, we will invest and design a range of AI for development (AI4D) initiatives, focusing on innovations, foundations and governance. These initiatives will support relevant community building, research, develop AI applications that are inclusive, ethical, and rights-based, and strengthen and create appropriate capacity building programs.
Activities of the African AI network
The main purpose of the AI for Development (AI4D) Africa project is to support a network of excellence in AI in sub-Saharan Africa to strengthen and develop community scientific and technological excellence in a range of AI-related issue areas. Specifically, the project will run 4 activities:
Develop a network of institutions and individuals working on and researching AI from across sub-Saharan Africa, via workshops and consultations
Deliver an AI research agenda with a focus on ethical, legal and social aspects of AI research
Generate an AI capacity building agenda via a survey of universities
Issue a call for at least ten multidisciplinary innovation projects within and outside the network, exploring local frontiers of research in AI
Additionally, the project will consider effective capacity building approaches based on identified policy and educational frameworks within the target countries.
Building on existing work
The project will draw from the recent K4A, IDRC and UNESCO supported mapping and PASCAL2 Network to facilitate a bottom-up network/community of researchers who will investigate and recommend how the network/community should shape its research agenda and actions.
Connection to other networks
The project will seek to align with Humane AI, a European FET Flagship Project Proposal for new ethical, trustworthy, AI technologies to enhance human capabilities and empower citizens and society. The project includes three major European AI communities such as ELLIS, CLAIRE and PASCAL.
Timeline
AI4D Africa will be starting Dec 2018 and run for 18 months and result in the establishment of the network, a research “roadmap”, a portfolio of innovation projects, and recommendations for capacity building for ethical and locally relevant AI research around the African continent.
International Development Programme
Global South map of emerging areas in Artificial Intelligence
A developing countries map of talents, players, knowledge and co-creation hot spots in AI
Artificial Intelligence (AI) is a key technology for the further development of the Internet and all future digital devices and applications. At this point the rapid growth of talent, projects, companies, research outputs, etc. has fuelled sectors ranging from data analytics and Web platforms to driverless vehicles and new generation of robots for our homes, hospitals, farms or factories.
The total potential is not defined as there is no comprehensive study on “all things AI”. We therefore prepared a global map of talents, players, knowledge and co-creation hot spots in AI in emerging economies.
Multiple helix approach needed
Research and innovation, investments and business dynamics in AI are increasingly being influenced by the development of interactions among all stakeholders (“multiple helix” approach). More actors are involved in AI knowledge creation and the innovation process. Universities and research institutions collaborate with business enterprises, hospitals, local municipalities, public services providers and citizen organisations.
At the same time, research, innovation and business processes are changing with the transition towards open science, open innovation and open education, with rapid increase of funding in AI, as well as the computational capacity. The focus is increasingly on developing, testing and rolling out a large number of solutions for the benefit of citizens and local jobs.
This shows the way for new hot-spots of AI knowledge and co-creation globally. The challenge is to map the landscape across countries and understand what is out there in-the-wild.
Work done
The Canadian company ElementAI has created a Global AI Talent Report 2018 summarizing their research into the scope and breadth of the worldwide AI talent pool. Although their data visualizations map the distribution of worldwide talent at the start of 2018, they present a predominantly Western-centric model of AI expertise.
However, the second half of the report focuses on a qualitative assessment of talent and funding in Asia and Africa, but the reliability of numbers drops off significantly and does not match the industry or academic output of these hotspots.
We identified this approache as de-centralised and lacking in objective and therefore aimed the project to fill the gaps that ElementAI report has not been able to map.
Instead we focused on presenting a complete bottom-up “Emerging economies Artificial Intelligence ecosystem”, which proves to be a highly effective approach in Global South countries, due to the lack of structured data.
Need for large-scale objectives
The aim of the “Emerging economies Artificial Intelligence ecosystem” is to:
Create a bottom-up mapping via a community of AI ambassadors
Focus on the AI distribution in developing countries, specifically in low-middle income countries in 4 regions (Latin America/Caribbean, SSA, MENA, Asia)
Deliver an extensive list of AI players in developing countries and infographics
Create first global directory for AI hot spots, and matching SDGs.
The “Emerging economies Artificial Intelligence ecosystem” identified players in three clusters:
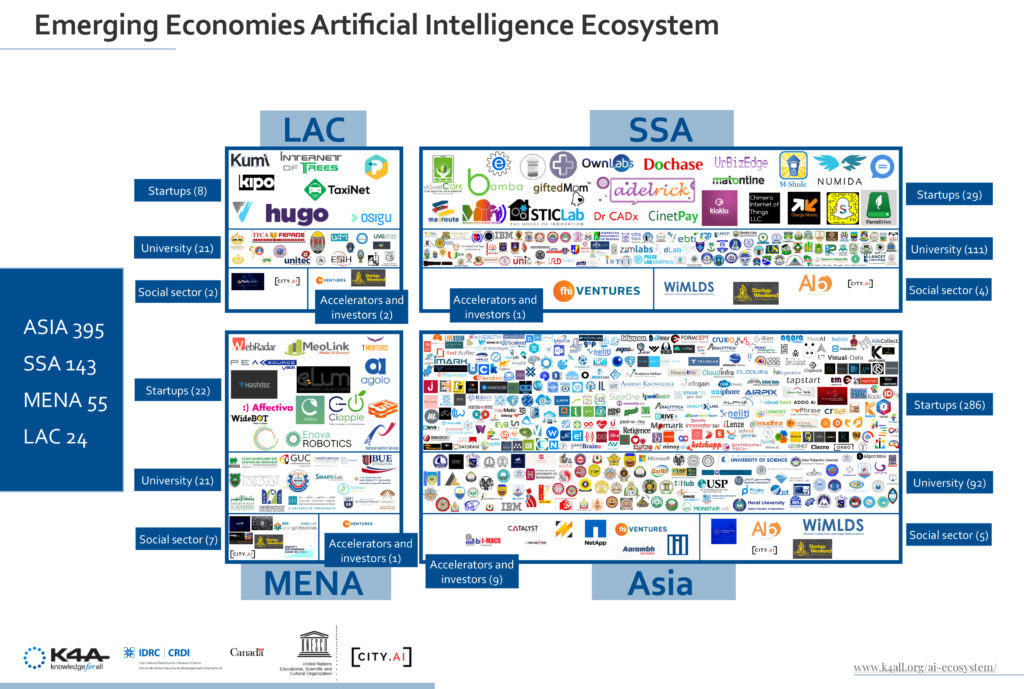
The Web directory of institutions in AI emerging markets cover 4 regions, ASIA, LAC, MENA, and SSA. The total mapping has produced in total 617 entities with the following breakdown per region.
Bottom-up mapping of players
The methodology includes manual mapping (bottom-up) by using our researcher network and partner sites and City.AI community in each country/region.
ElementAI used (i) results from several LinkedIn searches, which show the total number of profiles according to their own specialized parameters, (ii) captured the names of leading AI conference presenters who were considered to be influential experts in their respective fields of AI, (iii) relied on other reports and anecdotes from the global community.
We built on these results and made use of City.AI ambassadors which are hosting quarterly community gatherings world-wide. They foster their local ecosystems by curating high-quality talks from AI experts who focus on the lessons learned and challenges they face when putting AI into production.
Breakdown of AI ecosystems in regions
Latin America and Caribbean Artificial Intelligence ecosystem
Sub-Saharan Africa Artificial Intelligence ecosystem
Middle East and North Africa Artificial Intelligence ecosystem
Asian Artificial Intelligence ecosystem
The selection comprises of bottom-up mapped entities from 33 countries and researchers still submitting weekly updates with information from the field.
ASIA has a total of 399 players in AI: Academia (92), Accelerators and Investors (9), Corporates (6), Social sector (2) and Start-ups (286), countries include Georgia, India, Pakistan, Sri Lanka, Indonesia, Lao, Nepal, Philippines, Vietnam, Bangladesh, Cambodia, Mongolia and Myanmar.
SSA has a total of 149 players in AI: Academia (111), Accelerators and Investors (1), Corporates (2), and Start-ups (29), countries included are Kenya, Nigeria, Zimbabwe, Mozambique, Senegal, Congo, Ivory Coast, Cameroon and Uganda.
MENA has a total of 57 players in AI: Academia (21), Accelerators and Investors (1), Corporates (2), Social sector (9) and Start-ups (22), countries included are Morocco, Egypt, Jordan, Tunisia and Syrian Arab Republic.
LAC has a total of 36 players in AI: Academia (21), Accelerators and Investors (1), Corporates (1), Social sector (1), countries included are Haiti, El Salvador, Bolivia, Guatemala and Honduras.
Regions are emerging strong
The directory has quantitative value, as it presents for the first time a bottom-up mapping of AI entities in the 4 regions, however it has also qualitative value by unearthing anecdotal data, an immediate example is a university in Madagascar which has no Web presence, but is running an AI teaching programme. No other methodology could unearth such data.
We have piloted this action with the European project in AI in OER titled X5GON which aims at creating a platform to deliver globally accessible Open Educational Resources in Machine Learning. Three X5GON partners currently have positions as UNESCO Chairs in OER and the newly established UNESCO Chair in Artificial Intelligence with chair holder John Shawe-Taylor.
Starting a new global AI research network
The results will be used to bootstrap a series of AI research networks starting from the SSA region. This initial list of 600+ players will serve as a basis for capacity building toconnect the landscape and offer evidence and guidance ranging from AI based policies to capacity building, research methods, use cases, deployment, exploration, exploitation and operability, applied to all SDG sectors.
Extending the directory
Caveats include the following:
The mapping of the country entities is subjective: although they are normally based directly on input from country experts, only a few experts per country and per region could be consulted in the time available
On the whole, judgements of what fits into the category of AI are taken at face value, though the researchers looked for URLs to confirm each entity expertise and credibility made about specific institutions
The research outcomes presented in the study are not intended to be exhaustive about the state-of-the-art of AI across UNESCO Member States – in particular the research team did not run an extensive general analysis into matching AI companies with SDGs
A considerable number of countries and UNESCO member states have some kind of initiative with regard to AI, but there is still a long way to go, both in mapping these MS deeper and drill into research and industrial directions and expertise. In most MS the vision of AI is rather broad. We are not sure how this vision is applied to actual policy and commerce, as our approach is still limited.
International Development Research Centre is a Canadian federal Crown corporation that invests in knowledge, innovation, and solutions to improve lives and livelihoods in the developing world
UNESCO’s Communication and Information Sector (CI), Section for ICT in Education, Science and Culture (CI/KSD/ICT)
City.AI is a global non-profit network headquartered in the Netherlands. AI practitioners across 55+ cities on 6 continents are connecting, learning and sharing with the ultimate goal to enable everyone to apply AI. 170+ local ambassadors are the local community leaders and the backbone of City.AI