Data
To download the training/validation data, see the development kit.
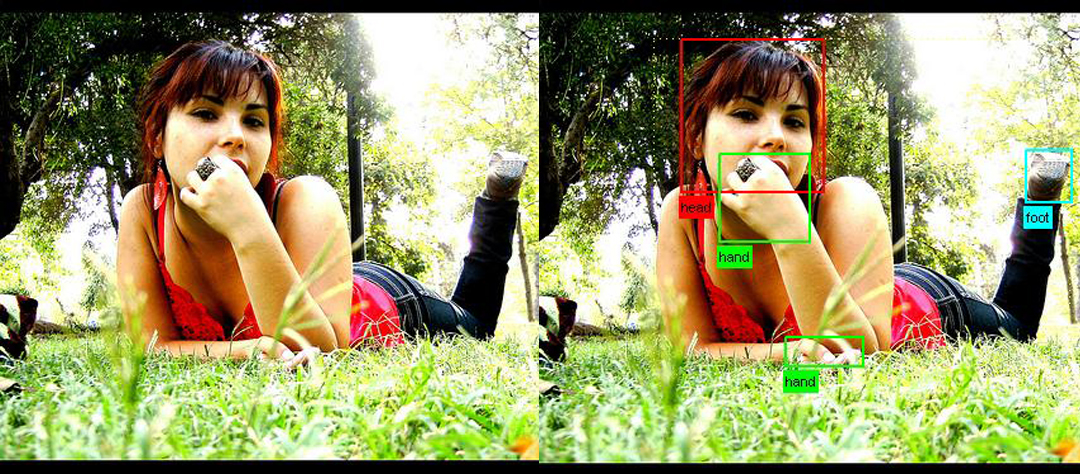
The training data provided consists of a set of images; each image has an annotation file giving a bounding box and object class label for each object in one of the twenty classes present in the image. Note that multiple objects from multiple classes may be present in the same image. Some example images can be viewed online. A subset of images are also annotated with pixel-wise segmentation of each object present, to support the segmentation competition. Some segmentation examples can be viewed online.
Annotation was performed according to a set of guidelines distributed to all annotators.
The data will be made available in two stages; in the first stage, a development kit will be released consisting of training and validation data, plus evaluation software (written in MATLAB). One purpose of the validation set is to demonstrate how the evaluation software works ahead of the competition submission.
In the second stage, the test set will be made available for the actual competition. As in the VOC2008-2010 challenges, no ground truth for the test data will be released.
The data has been split into 50% for training/validation and 50% for testing. The distributions of images and objects by class are approximately equal across the training/validation and test sets. In total there are 28,952 images. Further statistics are online.
Example images
Example images and the corresponding annotation for the classification/detection/segmentation tasks, and and person layout taster can be viewed online:
Development Kit
The development kit consists of the training/validation data, MATLAB code for reading the annotation data, support files, and example implementations for each competition.
The development kit will be available according to the timetable.
Test Data
The test data is now available. Note that the only annotation in the data is for the layout/action taster competitions. As in 2008-2010, there are no current plans to release full annotation – evaluation of results will be provided by the organizers.
The test data can now be downloaded from the evaluation server. You can also use the evaluation server to evaluate your method on the test data.
Useful Software
Below is a list of software you may find useful, contributed by participants to previous challenges.
Timetable
- May 2011: Development kit (training and validation data plus evaluation software) made available.
- June 2011: Test set made available.
- 13 October 2011 (Thursday, 2300 hours GMT): Extended deadline for submission of results. There will be no further extensions.
- 07 November 2011: Challenge Workshop in association with ICCV 2011, Barcelona.
Submission of Results
Participants are expected to submit a single set of results per method employed. Participants who have investigated several algorithms may submit one result per method. Changes in algorithm parameters do not constitute a different method – all parameter tuning must be conducted using the training and validation data alone.
Results must be submitted using the automated evaluation server:
It is essential that your results files are in the correct format. Details of the required file formats for submitted results can be found in the development kit documentation. The results files should be collected in a single archive file (tar/tgz/tar.gz).
Participants submitting results for several different methods (noting the definition of different methods above) should produce a separate archive for each method.
In addition to the results files, participants will need to additionally specify:
- contact details and affiliation
- list of contributors
- description of the method (minimum 500 characters) – see below
New in 2011 we require all submissions to be accompanied by an abstract describing the method, of minimum length 500 characters. The abstract will be used in part to select invited speakers at the challenge workshop. If you are unable to submit a description due e.g. to commercial interests or other issues of confidentiality you must contact the organisers to discuss this. Below are two example descriptions, for classification and detection methods previously presented at the challenge workshop. Note these are our own summaries, not provided by the original authors.
- Example Abstract: Object classification
Based on the VOC2006 QMUL description of LSPCH by Jianguo Zhang, Cordelia Schmid, Svetlana Lazebnik, Jean Ponce in sec 2.16 of The PASCAL Visual Object Classes Challenge 2006 (VOC2006) Results. We make use of a bag-of-visual-words method (cf Csurka et al 2004). Regions of interest are detected with a Laplacian detector (Lindeberg, 1998), and normalized for scale. A SIFT descriptor (Lowe 2004) is then computed for each detection. 50,000 randomly selected descriptors from the training set are then vector quantized (using k-means) into k=3000 “visual words” (300 for each of the 10 classes). Each image is then represented by the histogram of how often each visual word is used. We also make use a spatial pyramid scheme (Lazebnik et al, CVPR 2006). We first train SVM classifiers using the chi^2 kernel based on the histograms of each level in the pyramid. The outputs of these SVM classifiers are then concatenated into a feature vector for each image and used to learn another SVM classifier based on a Gaussian RBF kernel.
- Example Abstract: Object detection
Based on “Object Detection with Discriminatively Trained Part Based Models”; Pedro F. Felzenszwalb, Ross B. Girshick, David McAllester and Deva Ramanan; IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 32, No. 9, September 2010. We introduce a discriminatively-trained parts-based model for object detection. The model consists of a coarse “root” template of HOG features (Dalal and Triggs, 2006), plus a number of higher-resolution part-based HOG templates which can translate in a neighborhood relative to their default position. The responses of the root and part templates are combined by a latent-SVM model, where the latent variables are the offsets of the parts. We introduce a novel training algorithm for the latent SVM. We also make use of an iterative training procedure exploiting “hard negative” examples, which are negative examples incorrectly classified in an earlier iteration. Finally the model is scanned across the test image in a “sliding-window” fashion at a variety of scales to produce candidate detections, followed by greedy non-maximum suppression. The model is applied to all 20 PASCAL VOC object detection challenges.
If you would like to submit a more detailed description of your method, for example a relevant publication, this can be included in the results archive.
Best Practice
The VOC challenge encourages two types of participation: (i) methods which are trained using only the provided “trainval” (training + validation) data; (ii) methods built or trained using any data except the provided test data, for example commercial systems. In both cases the test data must be used strictly for reporting of results alone – it must not be used in any way to train or tune systems, for example by runing multiple parameter choices and reporting the best results obtained.
If using the training data we provide as part of the challenge development kit, all development, e.g. feature selection and parameter tuning, must use the “trainval” (training + validation) set alone. One way is to divide the set into training and validation sets (as suggested in the development kit). Other schemes e.g. n-fold cross-validation are equally valid. The tuned algorithms should then be run only once on the test data.
In VOC2007 we made all annotations available (i.e. for training, validation and test data) but since then we have not made the test annotations available. Instead, results on the test data are submitted to an evaluation server.
Since algorithms should only be run once on the test data we strongly discourage multiple submissions to the server (and indeed the number of submissions for the same algorithm is strictly controlled), as the evaluation server should not be used for parameter tuning.
We encourage you to publish test results always on the latest release of the challenge, using the output of the evaluation server. If you wish to compare methods or design choices e.g. subsets of features, then there are two options: (i) use the entire VOC2007 data, where all annotations are available; (ii) report cross-validation results using the latest “trainval” set alone.
Policy on email address requirements when registering for the evaluation server
In line with the Best Practice procedures (above) we restrict the number of times that the test data can be processed by the evaluation server. To prevent any abuses of this restriction an institutional email address is required when registering for the evaluation server. This aims to prevent one user registering multiple times under different emails. Institutional emails include academic ones, such as name@university.ac.uk, and corporate ones, but not personal ones, such as name@gmail.com or name@123.com.
Publication Policy
The main mechanism for dissemination of the results will be the challenge webpage.
The detailed output of each submitted method will be published online e.g. per-image confidence for the classification task, and bounding boxes for the detection task. The intention is to assist others in the community in carrying out detailed analysis and comparison with their own methods. The published results will not be anonymous – by submitting results, participants are agreeing to have their results shared online.
Citation
If you make use of the VOC2011 data, please cite the following reference (to be prepared after the challenge workshop) in any publications:
@misc{pascal-voc-2011,
author = "Everingham, M. and Van~Gool, L. and Williams, C. K. I. and Winn, J. and Zisserman, A.",
title = "The {PASCAL} {V}isual {O}bject {C}lasses {C}hallenge 2011 {(VOC2011)} {R}esults",
howpublished = "http://www.pascal-network.org/challenges/VOC/voc2011/workshop/index.html"}
Database Rights
The VOC2011 data includes images obtained from the “flickr” website. Use of these images must respect the corresponding terms of use:
For the purposes of the challenge, the identity of the images in the database, e.g. source and name of owner, has been obscured. Details of the contributor of each image can be found in the annotation to be included in the final release of the data, after completion of the challenge. Any queries about the use or ownership of the data should be addressed to the organizers.
Organizers
- Mark Everingham (University of Leeds), m.everingham@leeds.ac.uk
- Luc van Gool (ETHZ, Zurich)
- Chris Williams (University of Edinburgh)
- John Winn (Microsoft Research Cambridge)
- Andrew Zisserman (University of Oxford)
Acknowledgements
We gratefully acknowledge the following, who spent many long hours providing annotation for the VOC2011 database:
Yusuf Aytar, Jan Hendrik Becker, Ken Chatfield, Miha Drenik, Chris Engels, Ali Eslami, Adrien Gaidon, Jyri Kivinen, Markus Mathias, Paul Sturgess, David Tingdahl, Diana Turcsany, Vibhav Vineet, Ziming Zhang.
We also thank Sam Johnson for development of the annotation system for Mechanical Turk, and Yusuf Aytar for further development and administration of the evaluation server.
Support
The preparation and running of this challenge is supported by the EU-funded PASCAL2 Network of Excellence on Pattern Analysis, Statistical Modelling and Computational Learning.
We are grateful to Alyosha Efros for providing additional funding for annotation on Mechanical Turk.