Cracking the Language Barrier for a Multilingual Africa
The objective of this project is to build a Wolof text-to-speech system. Three people will be involved Thierno Ibrahima DIOP, senior data scientist at Baamtu SARL, El Hadj Mamadou Nguer, Assistant Professor at Universite Virtuelle du Senegal, and Sileye BA, Senior machine learning researcher at L’Oreal Innovation Center, in Paris. Thierno Ibrahima DIOP, and Mamadou Nguer will be the project’s principal investigators.
The project will exploit a dataset of 40000 Wolof phrases uttered by two actors. This open-source dataset is a deliverable of a previous project.
The project will be conducted following four phases:
1. Evaluation of the quality of the dataset
2. Implementation of a machine learning model mapping Wolof texts into their
corresponding utterances
3. Quantitative and qualitative evaluation of the implemented model’s performances
4. Development of and API exposing implemented text to speech model
Database quality will be assessed on a randomly sampled portion of about a thousand uttered phrases. These phrases will be qualitatively validated in terms of comprehensiveness by fluent Wolof speakers.
A state of the art in neural network speech synthesizer will be implemented and evaluated using the dataset. Neural network models have been selected as they can be trained end to end without requiring word segmentation at the phoneme level as required by competing statistical models. We will investigate Text-to-Spectrogram models such as Tacotron, Glow-TTS, Speedy-Speech, and also Vocoders models such as MelGAN.
The trained model will be evaluated quantitatively and qualitatively. The quantitative evaluation will be done using metrics provided in standard text to speech evaluation libraries. The qualitative evaluation will be based on fluent Wolof speakers’ comprehension of synthesized Wolof utterances.
The model will be exposed via an API which will take as input a language token and input text, and returns the synthesized input text into an audio file. This API will be plugged to à web platform based on the Masakhane MT web platform.
For the deployment a kubernetes cluster will be used to have a horizontal scaling, in the beginning, we can have only one instance, and depending on the load, the number will be automatically adjusted. The cost of an instance (8 cores, 32GB of RAM) will be about $83.95 per Month subject to a yearly reservation basis.
An objective of this project is to publish work done on the dataset, and the developed speech synthesis model in a natural language processing conference such as African NLP Workshop, or Deep Learning Indaba. This will give more visibility to this work, and at the same time advances machine learning based African language processing activities.
AI4D Programme
End-to-End Learning for Autonomous Driving on Unpaved Roads – A Study Towards Automated Wildlife Patrol
Funded by the AI4D Programme
Introduction
Wildlife tourism is a significant and growing contributor to the economic and social development in the African region through revenue generation, infrastructure development and job creation. According to a recent press release by the World Travel and Tourism Council [1], travel and tourism contributed $194.2 billion (8.5% of GDP) to the African region in 2018 and supported 24.3 million jobs (6.7% of total employment). Globally, travel and tourism is a $7.6 trillion industry, and is responsible for an estimated 292 million jobs [2]. Tourism is also one of the few sectors in which female labor participation is already above parity, with women accounting for up to 70% of the workforce [2].
However, the wildlife tourism industry in Africa is increasingly threatened by rising human population and wildlife crime. As poaching becomes more organised and livestock incursions become frequent occurrences, shortages in ranger workforce and shortcomings in technological developments in this space have put thousands of species at risk of endangerment, and threaten to collapse the wildlife tourism industry and ecosystem.
Tourism in Kenya contributed a revenue of $1.5 billion in 2018 [3]. And The National Wildlife Conservation Status Report, 2015 – 2017 [4] presented by the Ministry of Tourism and Wildlife of Kenya claimed that wildlife conservancies in Kenya supported over 700,000 community livelihoods. The recession of the wildlife tourism industry could therefore have major adverse economic and social impacts on the country. It is thus critical that sustainable solutions are reached to save the wildlife tourism industry, and further research is fuelled in this area.
Problem definition
According to The National Wildlife Conservation Status Report, 2015 – 2017 [4] presented by the Ministry of Tourism and Wildlife of Kenya, there is currently a shortage of 1038 rangers, from the required 2484 rangers in Kenyan national parks and reserves, a deficit of over 40%. To address shortages in ranger workforce, carry out monitoring activities more effectively, and detect criminal or endangering activities with greater precision, we propose the deployment of Unmanned Ground Vehicles (UGVs) for intelligent patrol and wildlife monitoring across the national parks and reserves in Kenya.
The UGVs would be fitted with a suite of cameras and sensors that would enable it to navigate autonomously within the parks, and run multiple deep learning and computer vision algorithms that can carry out numerous monitoring activities such as detection of poaching, livestock incursions, human wildlife conflict, distressed wildlife, and species identification.
The UGVs could be monitored from a central surveillance system, where alerts can be generated on detection of any alarming activity, and rangers dispatched to respond. Ethical considerations can be made to facilitate the deployment of these UGVs in a manner that aids the ranger workforce in their routine surveillance tasks throughout the national parks and reserves that often span thousands of square kilometers, rather than replace them. Sustainable and ethical automation could help create more jobs in the automotive and technology sectors without replacing current jobs.
The deployment of a project of this scale, however, would require significant investments in building the UGV, and require feasibility studies from the government and international wildlife conservation bodies. Furthermore, without reasonable computer vision and autonomous navigation accuracies, investments towards building the unmanned vehicle would be futile. It is thus crucial that efforts are first made towards solving the computer vision and autonomous navigation challenges posed by the rough terrains prevalent in national parks and reserves.
This project therefore serves as a stepping-stone towards adopting autonomous vehicle technology in Africa and pioneering further research in the field and its applications to broader areas beyond just transportation. Additionally, its adaptation in national park environments would allow it to be tested in unstructured environments lacking road infrastructure and free of traffic and pedestrians, thus allowing the systems to be tested safely and get quicker policy approvals. The scope of this research is hence limited to developing an end-to-end deep learning model that can autonomously navigate a vehicle over dirt roads and challenging terrain that is present in national parks and reserves.
The model will be trained on trail video as well as driving data such as steering wheel angle, speed, acceleration, and Inertial Measurement Unit (IMU) data. The accuracy of the model will be measured by calculating the error rate between the model’s prediction and the driver’s actual inputs over a given distance. We also look to publish the dataset of annotated driving data from national parks and reserves, the first of its kind, to encourage further research in this space. Additionally, we shall collect metadata such as number of patrol vehicles per square kilometer, average distance travelled per vehicle per day, distance of traversable road in the park per square kilometer, that can be used to give a preliminary analysis on the feasibility of the project results towards automated wildlife patrol.
References
[1] “African tourism sector booming – second-fastest growth rate in the world”, WTTC press release, Mar. 13, 2019. Accessed on Jul. 11, 2019. [Online]. Available:
https://www.wttc.org/about/media-centre/press-releases/press-releases/2019/african-tourism-sector-booming-second-fastest-growth-rate-in-the-world/
[2] “Supporting Sustainable Livelihoods through Wildlife Tourism”, World Bank Group, 2018.
[3] “Tourism Sector Performance Report – 2018”, Hon. Najib Balala, 2018.
[4] “The National Wildlife Conservation Status Report, 2015 – 2017”, pp. 131, 74, 75 Ministry of Tourism and Wildlife, Kenya, 2017.
AI4D Programme
AI4D Malawi News Classification Challenge
Cracking the Language Barrier for a Multilingual Africa
Algorithms for text classification still contain some open problems for example dealing with long pieces of texts and with texts in under-resourced languages.
This challenge gives participants the opportunity to improve on text classification techniques and algorithms for text in Chichewa. The texts are of varying length, some being quite long and will pose some challenges in chunking and classification. The texts are made up of news articles.
The objective of this challenge is to classify news articles.
We hope that your solutions will illustrate some challenges and offer solutions.
Algorithms for text classification have come a long way, but classifying long texts and working with under-resourced languages can still pose difficulties. This challenge gives participants the opportunity to improve on text classification techniques and algorithms for text in Chichewa. The texts are made up of news articles or varying lengths. The objective of this challenge is to classify these articles by topic. We hope that your solutions will illustrate some challenges and offer solutions.
Chichewa is a Bantu language spoken in much of Southern, Southeast and East Africa, namely the countries of Malawi and Zambia, where it is an official language, and Mozambique and Zimbabwe where it is a recognised minority language.
tNyasa Ltd Data Science Lab
We are a company based in Malawi offering intelligent technological solutions for the travel, technology, trade, cultural and education sector in Malawi. Part of the data Science Lab we work on language tools for Chichewa such as the construction and curation of data sets, speech to text and information processing.
AI4D-Africa is a network of excellence in AI in sub-Saharan Africa. It is aimed at strengthening and developing community, scientific and technological excellence in a range of AI-related areas. It is composed of African Artificial Intelligence researchers, practitioners and policymakers.
Datasets
The data was collected from news publications in Malawi. tNyasa Ltd Data Science Lab have used three main broadcasters: the Nation Online newspaper, Radio Maria and the Malawi Broadcasting Corporation. The articles presented in the dataset are full articles and span many different genres: from social issues, family and relationships to political or economic issues.
The articles were cleaned by removing special characters and html tags.
Your task is to classify the news articles into one of 19 classes. The classes are mutually exclusive.
List of classes: [‘SOCIAL ISSUES’, ‘EDUCATION’, ‘RELATIONSHIPS’, ‘ECONOMY’, ‘RELIGION’, ‘POLITICS’, ‘LAW/ORDER’, ‘SOCIAL’, ‘HEALTH’, ‘ARTS AND CRAFTS’, ‘FARMING’, ‘CULTURE’, ‘FLOODING’, ‘WITCHCRAFT’, ‘MUSIC’, ‘TRANSPORT’, ‘WILDLIFE/ENVIRONMENT’, ‘LOCALCHIEFS’, ‘SPORTS’, ‘OPINION/ESSAY’]
Files available for download:
Train.csv – contains the target. This is the dataset that you will use to train your model.
Test.csv- resembles Train.csv but without the target-related columns. This is the dataset on which you will apply your mode.
SampleSubmission.csv – shows the submission format for this competition, with the ‘ID’ column mirroring that of Test.csv. The order of the rows does not matter, but the names of the IDs must be correct.
Partners
AI4D-Africa; Artificial Intelligence for Development-Africa Network
AI4D Programme
AI4D Takwimu Lab – Machine Translation Challenge
Cracking the Language Barrier for a Multilingual Africa
Ewe and Fongbe are Niger–Congo languages, part of a cluster of related languages commonly called Gbe. Fongbe is the major Gbe language of Benin (with approximately 4.1 million speakers), while Ewe is spoken in Togo and southeastern Ghana by approximately 4.5 million people as a first language and by a million others as a second language. They are closely related tonal languages, and both contain diacritics that can make them difficult to study, understand, and translate.
Although those languages are at the core of the economic and social life of at least 3 major West African capital cities (namely Cotonou, Lome and Accra), they are today mostly spoken and very rarely written. Due to that fact (among other reasons), there is very little official or formal communication in those languages, leaving non-French/English speakers often unable to access critical facilities like education, banking, and healthcare. This challenge is part of an initiative that wishes to bring down the barriers between African local language speakers and modern society.
The objective of this challenge is to create a machine translation system capable of converting text from French into Fongbe or Ewe. You may train one model per language or create a single model for both. You may not use any external data, so a key component of this competition is finding a way to work with the available data efficiently.
This is a pioneer competition as far as low-resourced West African languages are concerned. A good solution would be a model that can be improved upon or used by researchers across the world to create APIs that can be integrated into day-to-day tools like ATMs, delivery applications etc., and help bridge the gap between rural West Africa and the modernized services.
This competition is one of five NLP challenges we will be hosting on Zindi as part of AI4D’s ongoing African language NLP project, and is a continuation of the African language dataset challenges we hosted earlier this year. You can read more about the work here.
TakwimuLab is an association of francophone west african who are professionals and enthusiasts about AI technologies. Our goal is to spread awareness about the challenges AI can help solve in our communities, disseminate knowledge and build solutions that can resolve real issues in our countries. Takwimu Lab is based in Benin.
Data
This is a parallel corpus dataset for machine translation from French to Ewe and French to Fongbe, languages from Togo and Benin respectively. It contains roughly 23 000 French to Ewe and 53 000 French to Fongbe parallel sentences, collected from blogs, tales, newspapers, daily conversations, webpages and annotated for neural machine translation. The collected sentences were preprocessed and aligned manually.
Variable definitions
ID : Unique identifier of the text
French : Text in French
Target_Laguauge: The target language
Target : Text in Fongbe or Ewe
Files available for download:
Train.csv – contains parallel sentences for training your model or models. There are 77,177 rows, of which 53,366 are French-Fongbe and 23,811 are French-Ewe
Test.csv- resembles Train.csv but without the Target column. This is the dataset on which you will apply your model(s).
SampleSubmission.csv – shows the submission format for this competition, with the ID column mirroring that of Test.csv and the ‘Target’ column containing your translation in Ewe or Fongbe. The order of the rows does not matter, but the names of the ‘ID’ must be correct.
Partners
AI4D-Africa; Artificial Intelligence for Development-Africa Network
AI4D Programme
AI4D iCompass Social Media Sentiment Analysis for Tunisian Arabizi
Cracking the Language Barrier for a Multilingual Africa
On social media, Arabic speakers tend to express themselves in their own local dialect. To do so, Tunisians use ‘Tunisian Arabizi’, where the Latin alphabet is supplemented with numbers. However, annotated datasets for Arabizi are limited; in fact, this challenge uses the only known Tunisian Arabizi dataset in existence.
Sentiment analysis relies on multiple word senses and cultural knowledge, and can be influenced by age, gender and socio-economic status.
For this task, we have collected and annotated sentences from different social media platforms. The objective of this challenge is to, given a sentence, classify whether the sentence is of positive, negative, or neutral sentiment. For messages conveying both a positive and negative sentiment, whichever is the stronger sentiment should be chosen. Predict if the text would be considered positive, negative, or neutral (for an average user). This is a binary task.
Such solutions could be used by banking, insurance companies, or social media influencers to better understand and interpret a product’s audience and their reactions.
This competition is one of five NLP challenges we will be hosting on Zindi as part of AI4D’s ongoing African language NLP project, and is a continuation of the African language dataset challenges we hosted earlier this year. You can read more about the work here.
About Icompass
iCompass is a Tunisian startup, created in July, 2019 and labelled startup act in August 2019. iCompass is specialized in the Artificial Intelligence field, and more particularly in the Natural Language Processing field. The particularity of iCompass is breaking the language barrier by developing systems that understand and interpret local dialects, especially African and Arab ones.
Partners
AI4D-Africa; Artificial Intelligence for Development-Africa Network
AI4D Programme
AI4D Yorùbá Machine Translation Challenge
Cracking the Language Barrier for a Multilingual Africa
Machine translation (MT) is a popular Natural Language Processing (NLP) task which involves the automatic translation of sentences from a source language to a target language. Machine translation models are very sensitive to the domain they were trained on which limit their generalization to multiple domains of interest like legal or medical domains. The problem is more severe in low-resource languages like Yorùbá where the most available datasets used for training are in the religious domain like JW300.
How can we train MT models to generalize to multiple domains or quickly adapt to new domains of interest? In this challenge, you are provided with 10,000 Yorùbá to English parallel sentences sourced from multiple domains like news articles, ted talks, movie transcripts, radio transcripts, software localization texts, and other short articles curated from the web. Your task is to train a multi-domain MT model that will perform very well for practical use cases.
The goal of this challenge is to build a machine translation model to translate sentences from Yorùbá language to English language in several domains like news articles, daily conversations, spoken dialog transcripts and books. Your solution will be judged by how well your translation prediction is semantically similar to the reference translation.
The translation models developed will assist human translators in their jobs, help English speakers to have better communication with native speakers of Yorùbá, and improve the automatic translation of Yorùbá web pages to English language.
This competition is one of five NLP challenges we will be hosting on Zindi as part of AI4D’s ongoing African language NLP project, and is a continuation of the African language dataset challenges we hosted earlier this year. You can read more about the work here.
About Masakhane
Masakhane is the open research, participatory, grassroots NLP initiative for Africans by Africans, with the aim of putting African research in NLP on the map, by holistically tackling the problems facing society. Founded in 2019, Masakhane has since garnered over 400 researchers from over 30 African countries, published state of the art research for over 38 African languages at various venues, and has built a thriving community. Masakhane’s participatory approach has enabled researchers without formal scientific training to contribute data, evaluations and models to published research, by focusing on lowering the barriers of entry.
Partner
AI4D-Africa; Artificial Intelligence for Development-Africa Network
AI4D Programme
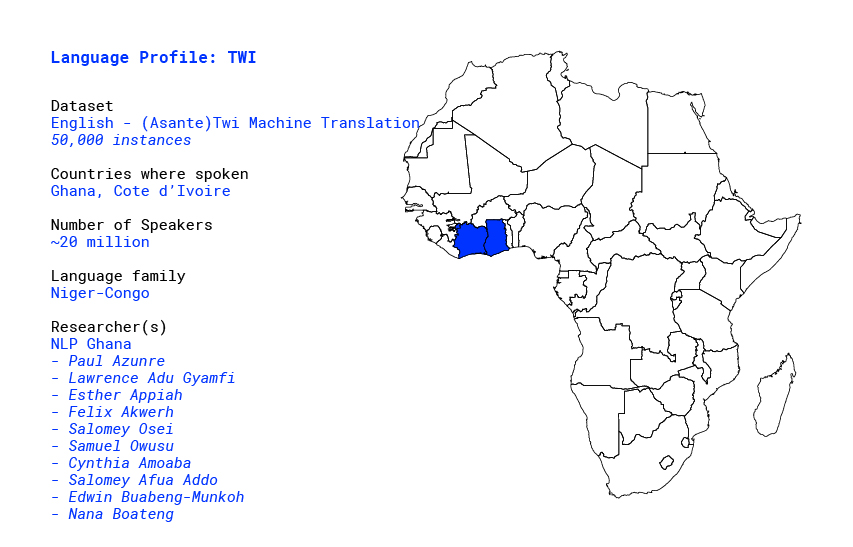
Building a database for Twi language in Africa
Cracking the Language Barrier for a Multilingual Africa
Description
Twi is arguably the most recognizable Akan Language natively spoken in parts of southern and central Ghana, as well as parts of Cote d’Ivoire. By some estimates it has approximately 20 million native speakers [1]. It is a tonal language. It comprises at least four distinct dialects, namely Asante, Akuapem, Fante and Bono. Asante is arguably the most widely spoken and common dialect.
Building a database for Twi language in Africa
Pertinence
In practice, knowing this language alone allows one to navigate most parts of Ghana. You are likely to find someone who at the very least understands the language in every part of Ghana.
Example Sentences
English
Twi
What is going on here?
Ɛdeɛn na ɛrekɔ so wɔ ha?
Wake up
Sɔre
She comes here every Friday
Ɔba ha Fiada biara
Learn to be wise
Sua nyansa
Prior Work
The website and app Kasahorow [2] has a rather limited set of translations. The JW300 dataset [3] has some (over ½ million) extremely noisy English to (Akuapem) Twi parallel translation sentence pairs. A noisy Wikipedia is available [4], but the volume and quality leave much to be desired [4]. Some 700 sentence pairs are available in the TC Akan Corpus [9].
A recent study [5], which investigated the quality of these data sources in the context of FastText embeddings constructed on Twi, found them to be woefully insufficient. It is the only modern computing study of Twi that we are aware of. We have since replicated and slightly improved these FastText embeddings [6], trained and shared a variety of embeddings from the Transformers/BERT family through the HuggingFace model repo [7] and crowd sourced close to 1000 manually curated translation pairs. We have also developed a fairly decent English-Twi translator (transformer-based seq2seq model) which we are hoping to refine on the data that this collaboration yields. You can find more information on our official and github pages [8].
Researcher Profile: Paul Azunre
Paul Azunre holds a PhD in Computer Science from MIT and has served as a Principal Investigator on several DARPA research programs. He founded Algorine, a Research Lab dedicated to advancing AI/ML and identifying scenarios where they can have a significant social impact. Paul also co-founded NLP Ghana, an open source initiative focused on using NLP and Transfer Learning with Ghanaian and other low-resource languages. He frequently contributes to peer-reviewed journals and has served as a program committee member at some ICML workshops in AutoML and NLP. He is the author of the “Transfer Learning for NLP” book recently published by Manning Publications.
Researcher Profile: Lawrence Adu-Gyamfi
A subsea installation engineer by profession with a background in Aerospace engineering. Currently devoting the rest of my off-work time to contributing to the activities of NLP Ghana, assisting with the collection of data, preprocessing them and making them ready for use in the models we are testing internally. Serving as the NLP Ghana Director of Product, overseeing how the different teams of NLP Ghana work together.
Researcher Profile:Esther Appiah
Esther Appiah holds a BA in Modern Languages from the Kwame Nkrumah University of Science and Technology with a Diploma in French Studies from the Université D’Abomey Calavi, Centre Beninois des Langues Étrangères (CEBELAE) in Benin. She is currently pursuing an MPhil in Theoretical Linguistics at UiT, Norway. Her language specialties include French, English and Akan. She has a vast experience spanning various sectors/industries on language use and interface with core tasks on writing, proofreading, translation and researching. She works with the Ghana NLP as a data researcher and ultimately hopes to specialise in Computational Linguistics to help streamline NLP processes in underrepresented African languages in the digital space.
Researcher Profile: Felix Akwerh
Felix is currently enrolled in a Masters program in Computer Science at the Kwame Nkrumah University of Science and Technology. He augments his education with online classes and Machine Learning events. He is actively involved in the development of natural language processing with Ghana NLP. He co-authored a paper on Artificial Intelligence in Construction for submission. He holds a Bsc in Mathematics at the Kwame Nkrumah University. He worked with the UITS-KNUST where he helped build a transport system and other software projects. His research interest lies in Machine Learning and NLP, specifically in neural conversational models.
Researcher Profile: Salomey Osei
Salomey holds a Master of Philosophy in Applied Mathematics and an Msc in both Industrial Mathematics and Machine Intelligence. She is a recipient of Google and Facebook Scholarship, MasterCard Foundation Scholarship amongst others. She is the team lead for unsupervised methods for Ghana NLP and a co organizer for Women in Machine Learning and Data Science Accra chapter (WiMLDS). She is also passionate about mentoring students, especially females in STEM and her long term goal is to share her knowledge with others by lecturing.
Researcher Profile: Samuel Owusu
Samuel Owusu is currently working as a data scientist for the Ministry of Finance, Ghana. He holds a BSc in Information Technology from Ghana Technology University College. He was a team member of the group that won 1st prize of Ghana’s maiden national hackathon organised by the World Bank and Ministry of Water Resources and Sanitation. His Research interest lies in NLP – Automatic Speech Recognition for low resourced languages. He is involved in developing open source curriculums in Machine Learning and Computer Science for young girls. Samuel is a life-long learner.
Researcher Profile: Cynthia Amoaba
Cynthia Amoaba is a high school graduate from Chemu Senior High School and a student at the University For Development Studies. She’s an Ambassador and founder of the first Women In Stem (WiSTEM) chapter in Ghana.She also founded the STEM club in her high school and looks forward to extending it to schools in deprived areas. Currently, she tutors high school students in her community in Physics and Maths and helps train school dropouts in beads and soap making. She’s a science enthusiast and looks forward to learning more through her involvement in the development of NLP with Ghana-NLP.
Researcher Profile: Salomey Afua Add
Salomey Afua Addo is the founder of Lighted Hope, a Non GovernmentalOrganization that seeks to promote literacy and coding skills among children living in slums in Ghana. She holds an MSc in Mathematical Sciences from the African Institute for Mathematical Sciences and a certificate in business management from the European School of Management and Technology, Berlin. She is the coding instructor for The Love Academy in the USA. Currently, she serves as a volunteer at Ghana NLP, and she plays a vital role in collecting and preprocessing data for the data team at Ghana NLP. Salomey Afua Addo lives a purpose driven life.
Researcher Profile: Edwin Buabeng-Munkoh
Edwin Buabeng-Munkoh is currently working as a Software Engineer at Huawei Technologies Ghana Limited. He holds a BSC in Computer Engineering from Kwame Nkrumah University of Science and Technology. He is enrolled in the Data Science Mentorship program with Notitia AI. He is actively involved in the development of natural language processing with GhanaNLP. He serves as a volunteer at Ghana NLP where he helps with preprocessing data for the data team. Along with his daily work he has enrolled and completed multiple online courses on Data Science, AI and NLP. His research interest lies in Machine Learning, NLP and Computer Vision. He plans to help build a world where language is not a barrier in education and good healthcare
Researcher Profile:Nana Boateng
Nana Boateng holds a PhD. in Statistics from The University of Memphis. He has three masters degrees in Statistics, Mathematics and Economics. He has worked as a Data Scientist for Companies such as Fiat Chrysler Automobiles, Nice Systems Inc and Baptist Memorial Hospital. He is interested in application of mathematics, statistics and economics principles in solving problems in healthcare, finance and several other industries. He has several peer-reviewed publications to his name. He is the founder of Rest Analytics which advises companies on how to apply machine learning to increase efficiency and productivity. He contributes to GhanaNLP in the area of supervised learning.
Partners
Partners in Cracking the Language Barrier for a Multilingual Africa
The designations employed and the presentation of material on these map do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or any area or of its authorities, or concerning the delimitation of its frontiers or boundaries. Final boundary between the Republic of Sudan and the Republic of South Sudan has not yet been determined. Final status of the Abyei area is not yet determined.
AI4D Programme
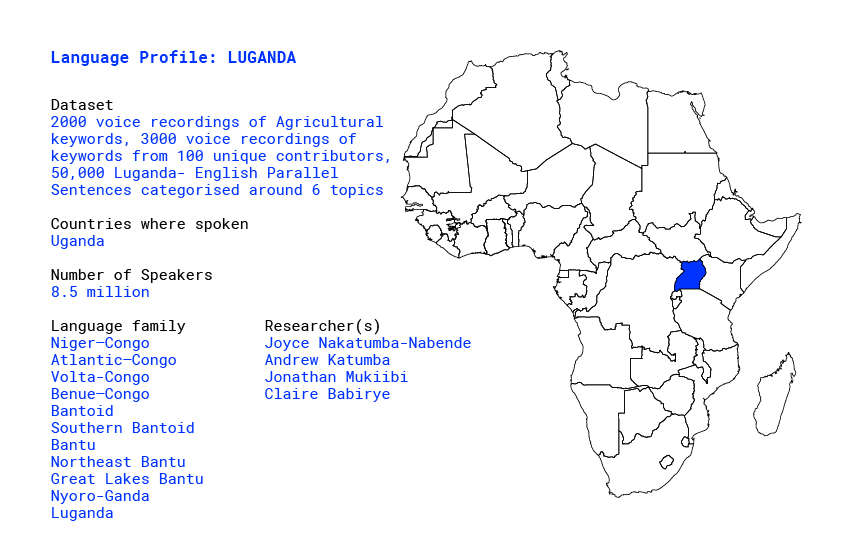
Building a database for Luganda language in Africa
Cracking the Language Barrier for a Multilingual Africa
Description
The Ganda language or Luganda is a Bantu language spoken in the African Great Lakes region. It is one of the major languages in Uganda, spoken by more than eight million Baganda and other people principally in central Uganda, including the capital Kampala of Uganda. It belongs to the Bantu branch of the Niger-Congo language family. Typologically, it is a highly-agglutinating, tonal language with subject-verb-object, word order, and nominative-accusative morphosyntactic alignment [1].
Language profile: Luganda
Building a database for Luganda language in Africa
With about six million first-language speakers in the Buganda region and a million others fluent elsewhere, it is the most widely spoken Ugandan language. As a second language, it follows English and precedes Swahili [1].
The language is used in all domains: education, media, telecommunication, trade, entertainment and in religious centres [2]. It has been used at lower institutions as pupils begin to learn English and until the 1960s, Luganda was also the official language of instruction in primary schools in Eastern Uganda [1]. It is also among the languages that have been tabled in the East African parliament to be selected as the official language for the East Africa Community [2].
Existing Work
As the use of the Luganda language is drastically growing across the different sectors from formal to informal, there has been work done on building a Luganda corpus and developing NLP models such as a Luganda text to speech machine [3]; English noun phrase to Luganda translator [4], smart Luganda language translator – given a source text in English it translates it to Luganda automatically [5]. To broaden access to search, a Luganda interface was launched for Google web search [6]. However, some of these applications have been developed based on minimal data.
In terms of language resources, there exists the Luganda Bible [7] which is an online Bible from the Word Project [13] and other religious books from the Jehovah’s Witnesses [12]. There exist some good online Luganda dictionaries like the globe dictionary [10], learn Luganda [9], Luganda phrasebook [9], learn Luganda concise [11] dictionary and Luganda Dictionary [8]. However, most of the available dictionaries are copyrighted and contain just a few word extracts in the language which results in a small representation for a language like Luganda where new words are being created and spoken every year.
Quite recently, a drive has been made by a team of researchers from the Makerere AI Lab [15] to add Luganda to the Common voice platform [14] and it is anticipated that through this project, a large voice dataset for building voice recognition models for Luganda will be generated.
Example of Sentence in Luganda
Luganda: Aboomukyalo bafuna nnyo mu by’obulimi.
English: The people in rural areas benefit a lot from agriculture.
Conclusion
With the regional integration of the East African Community in place, the use of the Luganda language has stretched boundaries from Uganda to the East African community, because most of the native speakers of this language are actively participating in this cooperation. It has been used to support inter-ethnic communication [2]. This, however, stretches beyond East Africa on the other hand.
Therefore, there is a need to build a robust Luganda dataset, which can be made publicly available so that different researchers can use it to build downstream applications such as machine translators, speech recognition machines, chatbots, virtual assistants, sentiment analytic models, in ensuring that information is accessible to all and also addressing some of the local-contextual problems with in the society.
Researcher Profile: Joyce Nakatumba-Nabende
Joyce Nakatumba-Nabende is a lecturer in the Department of Computer Science in Makerere University. She is also the head of the Makerere Artificial Intelligence and Data Science Lab in the College of Computing and Information Sciences. She obtained a PhD in Computer Science from Eindhoven University of Technology, The Netherlands. Her current research interests include Natural Languages Processing, Machine Learning, and Process Mining and Business Process Management. She is co-author of more than 20+ papers published in peer-reviewed international journals and conferences. She has supervised several PhD and Masters students in the field of Computer Science and Information Systems. She is a member of several international AI bodies that include Open for Good Alliance, Feministic AI Network and UN Expert Group Recommendation 3C Group on Artificial Intelligence.
Researcher Profile: Andrew Katumba
Andrew Katumba is a Lecturer in the Department of Electrical and Computer Engineering as well as a senior researcher with netLabs!UG, a research Center of Excellence in Telecommunications and Networking both in the College of Engineering, Design, Art & Technology (CEDAT), Makerere University. Andrew champions the research and applied Artificial Intelligence (AI) activities at netLabs!UG as the lead for the Marconi Society Machine Learning Lab. Andrew holds a PhD in Photonics and Machine Learning from the Gent University, Belgium. He has co-authored 50+ publications in peer-reviewed international journals and conferences and holds 2 patents in neuromorphic computing.
Researcher Profile: Jonathan Mukiibi
Jonathan Mukiibi is a computer science practitioner with a background in software engineering,linguistics, machine learning, big data and natural language processing. Over the past years he has been involved in artificial intelligence based projects like satellite image analysis, radio mining, social media mining, ambulance tracking and traffic which have been successfully implemented to solve real world problems in developing communities. Currently, he is pursuing a Masters in Computer Science at Makerere University where he is also doing research work at the AI and Data Science Research Lab. He is actively working on different NLP tasks but majorly doing research in end-to-end topic classification models for crop pests and disease surveillance from radio recordings.
Researcher Profile: Claire Babirye
Claire Babirye is a computer science professional with vast experience in different computing modules: from computer networks, computer security, network monitoring to machine learning, data science, natural language processing, deep learning technologies and use of technology for improved service delivery. She is a Research Assistant at the AI and Data Science Research Lab Makerere University and her role is to: tap into the revolution to obtain more and better data so as to support development work and humanitarian; support data analytics and visualization to generate patterns on insights on the data; develop machine learning models for classification. Within the domain of NLP, she has worked on tasks that involve: sentiment analysis on social media data and text classification to identify topics of interest from the farmer agricultural data.
Partners in Cracking the Language Barrier for a Multilingual Africa
Disclaimer
The designations employed and the presentation of material on these map do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or any area or of its authorities, or concerning the delimitation of its frontiers or boundaries. Final boundary between the Republic of Sudan and the Republic of South Sudan has not yet been determined. Final status of the Abyei area is not yet determined.
AI4D Programme
Keyword Spotting with African Languages
Senegal - Artificial Intelligence 4 Development Programme supported IndabaX community project
Motivation
Keyword spotting refers to the task of learning to detect spoken keywords. It interfaces all modern voice-based virtual assistants on the market: Amazon’s Alexa, Apple’s Siri, and the Google Home device. Contrarily to speech recognition models, keyword spotting doesn’t run on the cloud, but directly on the device. This sets up a natural constraint on the model size, energy consumption, and compute efficiency of the model because often the hardware devices have limited memory and limited computing power.
The prerequisite to perform such a task with African languages would be the creation of a dedicated dataset. Indeed, African languages account for 30.15% of the 7111 living languages (Orife et al. 2020), which provide great diversity. Unfortunately, they are barely represented in natural language processing (NLP) research.
The motivation of this proposal is to extend the Speech commands dataset (Warden 2018) with African languages. In particular, we are going to focus on 6 Senegalese languages: Wolof, Poular, Sérère, Mandingue, Diola, Soninké. Those are the most spoken languages in Senegal, and the first to be codified (given a written form) in 1971. There are two distinctions between a language and a dialect. In the case of Wolof, Poular, Mandingue, and Soninké there are many spoken dialects, each belonging to particular regions in Senegal.
Moreover, in this case, two speakers of different dialects within the same language may understand each other. In other words, the language is of common understanding for all the speakers of regional dialects. In the case of Sérère and Diola however, regional dialects differ dramatically, to the point that there is no common understanding for speakers of different dialects of the same language. In this case, the chosen language is the most spoken dialect within the language, the Sérère-Sine, and the Diola-Fogny.
Goals and outcomes
The Speech commands dataset (Warden 2018) included only a limited vocabulary composed of around twenty common words at its core. These included the digits from zero to nine, and seventeen words that would be useful as commands in IoT or robotics applications; “Yes”, “No”, “Up”, “Down”, “Left”, “Right”, “On”, “Off”, “Stop”, and “Go”, “Backward”, “Forward”, ”Bed”, “Bird”, “Cat”, “Dog”, “Tree”. This dataset has been collected specifically for keyword spotting referring to the task of learning to detect keywords. In short, the objective of this proposal is three-fold:
To produce open-source software dedicated to collecting data in an African context.
To build up an open-source extension of the Speech Commands dataset with Senegalese languages.
To document the dataset creation process and publish it, so that it could be reproduced in other countries. The interest here is to make the process reproducible in the African context
Concept and methodology
The first goal of the project is to produce open-source software dedicated to collect speech data in the African context. To do that, we are going to extend Common Voice so that it could mirror Amazon Mechanical Turk in an African context. Indeed, Common Voice is open-source software started by Mozilla to create a free database for speech recognition software. Common Voice natively allows users to create an account and to upload speech for a given text.
The account allows us to be sure that every recording comes from a different person. In addition, it also allows for a peer to peer validation, which could help for scaling. Amazon Mechanical Turk allows researchers to collect data from the internet by paying users a small amount of money, but is closed and only works with traditional payment solutions such as credit card or Paypal. However, mobile money is pervasive in most African countries. Thus, the main challenge for this deliverable is to connect Common Voice to mobile money solutions in Senegal, but the end goal would be to allow contributions in an open-source fashion to integrate with other mobile money actors in Africa like M-PESA.
For that purpose we made a successful partnership with Baamtu. As a technical partner, they are going to take care of all the cost relative to the web application development and deployment. Thierno Diop, one of the members of GalsenAI and Lead Data scientist at Baamtu, has won the AI4D-African Language Dataset Challenge in November 2019 with this methodology.
The second deliverable is to collect a dataset composed of 1000 recordings of the vocabulary in each language. For that purpose, we have made a strong multidisciplinary partnership with a team of linguists that is going to help to translate each word of the vocabulary in the six languages:
Wolof: Dr. Mamour Dramé Teacher Assistant, Department of Linguistics and Language Science, Faculty of Humanities, Cheikh Anta Diop University.
Poular: Mr. Moctar Baldé, Ph.D. Student in Linguistic and Teacher Assistant, Department of Linguistic and Language Science, Faculty of Humanities, Cheikh Anta Diop University.
Sérère : Mr. Edouard Diouf, Ph.D. Student in Linguistic and Teacher Assistant, Department of Linguistic and Language Science, Faculty of Humanities, Cheikh Anta Diop University.
Diola-Fogny : Mr. Pascal Assine, Ph.D. Student in Linguistic and Teacher Assistant, Department of Linguistic and Language Science, Faculty of Humanities, Cheikh Anta Diop University.
Mandingue: Dr. Mamadou Dabo, Teacher Assistant, Department of Linguistics and Language Science, Faculty of Humanities, Cheikh Anta Diop University.
Soninké: Mr. Almamy Konaté, Consultant Translator in Soninké.The dataset is going to be accessible on the GitHub page of the open-source project.
Finally, the third deliverable is to document the whole process and publish it in a technical report.
Greater narrative and ambition
The full impact of this project can be decomposed into two dimensions. (1) An open-source software with a reproducible process to create a dataset specifically in the African context. (2) A modeling challenge: keyword spotting with African languages that focuses on a practical machine learning task in a low resource setting. We argue that keyword spotting with African languages could have a widespread adoption within the African machine learning (ML) community and is, therefore, more likely to lead to breakthroughs and original contributions from Africa.
Low resource: Keyword spotting is a natural task to experiment with smaller models, requiring fewer resources to train (Warden 2018). It is relevant for the African ML research community who might work in limited-resource settings because of the systemic lack of funding in African research laboratories, besides, the majority of undergrad students might be under-equipped to run large models. Thus, alleviating the constraint of requiring a lot of computation and big datasets could harness the creativity of the African ML community. Indeed this trend has been acknowledged with the Practical ML for Developing Countries Workshop at ICLR 2020. We think that the current project reinforces this trend and could lead the African ML community toward academic leadership in resource constraint ML. Indeed, datasets and benchmarks have often played a significant role in pushing efforts toward discoveries, for instance, we can think of MNIST and ImageNet for that purpose.
Relevant and practical: We think that working with African language could have a wider adoption by the African ML community because we think that people have a genuine interest in developing tools for their language due to the intrinsic social value of languages. Moreover, as Africa has a strong oral tradition (Iwuji, 1989), we think that the general public could greatly benefit from services developed with their native language, which would encourage ML developers towards more innovation, which could lead to a virtuous circle of value creation.
Reproducibility and scalability: (1) open-source software allows any developer to adapt the software to feature local mobile money solutions. (2) Our methodology to select languages can then be used as a reference in that country to collect data for new languages. (3) The Github page of the project would then display a link to every new dataset created with the software. (4) Finally, as the validation procedure is expected to be performed in a peer to peer fashion. The data collection process is expected to scale with respect to the number of speakers willing to be recorded, and the number of people willing to validate the words from a given language.
Personnel
Jean Michel Ahmath Sarr – PhD Student in Computer Science, Department of Mathematics and Computer Science, Faculty of Science, Cheikh Anta Diop University. GalsenAI – IndabaX Senegal organizer
Daouda Tandiang Djiba – Data Scientist – BICIS Group BNP Paribas – GalsenAI – IndabaX Senegal organizer
Thierno Diop – Lead Data Scientist at Baamtu, cofounder of GalsenAI and Zindi Ambassador in Senegal – IndabaX Senegal organizer
Derguene Mbaye – Engineering Student in Telecoms & networks at Ecole Superieure
Polytechnique de Dakar, GalsenAI – IndabaX Senegal organizer
Elias waly Ba – Lead Data Scientist at Air Senegal – GalsenAI – IndabaX Senegal organizer
Ousseynou Mbaye – PhD Student in Computer Science, Department of Applied Sciences, Communication and Technologies, Alioune Diop University of Bambey – GalsenAI – IndabaX Senegal Organizer
Dr Mamour Dramé, Teacher
AI4D Programme
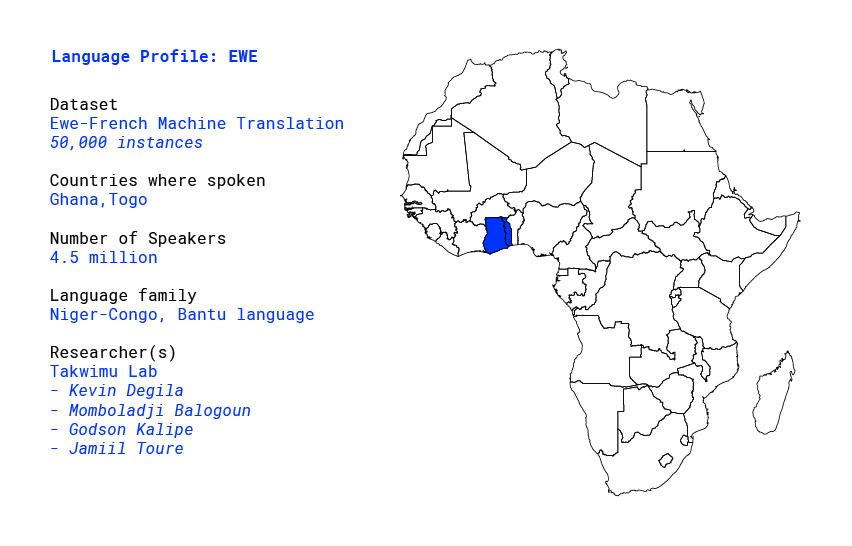
Building a database for Ewe language in Africa
Cracking the Language Barrier for a Multilingual Africa
Description
This dataset is part of a 3-4 month Fellowship Program within the AI4D – African Language Program, which was conceptualized as part of a roadmap to work towards better integration of African languages on digital platforms, in aid of lowering the barrier of entry for African participation in the digital economy.
This particular dataset is being developed through a process covering a variety of languages and NLP tasks, in particular Machine Translation of Ewe.
Language profile: Ewe
Language profile for Ewe
Overview
Ewe (Èʋe or Èʋegbe [èβeɡ͡be]) is a Niger–Congo language spoken in Togo and southeastern Ghana by approximately 4.5 million people as a first language and a million or so more as a second language.[1] Ewe is part of a cluster of related languages commonly called Gbe; the other major Gbe language is Fon of Benin. Like many African languages, Ewe is tonal.
Pertinence
In Togo and Ghana where ewe is heavily spoken, it is the main communication medium in major economic hubs especially in Togo where it is the most spoken language in the capital city Lome and also one of the two national languages of the country. In Ghana, ewe is part of the 11 government-sponsored languages apart from the official language english.[2] In 2020, the majority of children growing up in major cities in the Togo still picks up as their first language, a dialect of ewe depending on the region of the country they are from. The majority of the speakers at this day can speak ewe but not write it with the appropriate alphabet and orthography. The written communications in ewe usually happen using the english/french alphabet to write the sounds made by the words. Some schools in the capital offer ewe courses at secondary school level but those are generally optional and focus only on basics.
Nevertheless, in Togo, while the communication in schools and formally registered companies takes place in french, ewe remains the most used language in critical settings such as :
Market places
Medical centers
In apprenticeship for a major array of occupations such as hairdressing, tailoring, engine repairing, carpenting, agriculture among other manual jobs that make up 90% of the jobs and 30% of the GDP of the country. [3]
at police stations
in banking or telecommunications agencies
in shops and restaurants
Existing Work
Apart from sparse efforts of actors in the academic and literary fields and from some associations, there has not been any federated effort from the togolese government. Wycliffe-togo [4] is however one of the most prominent associations in the country organizing events and doing work to promote local languages. There exist a few ewe-english/french dictionaries online but the most popular ones remain the glosbe dictionary on the web [5], the Kasahorow Evegbe English Dictionary [6] and the mobile Ewe Dictionary [7] on the Android play store. In the academic world, a lot of work has been done especially regarding the tone, the syntax but also on other aspects such as the anthropological, lexicographical and phonological domains by both foreign and local (ghanain) researchers. [1]
Example of sentence in Ewe
Ewe : Ne ati aɖe le nya dim ɣesiaɣi le fíá wo ŋuti la, mumu ye le dzrom.
English : A tree which provokes axes wishes to be cut down.
Researcher Profile: Kevin Degila
Kevin is a Machine Learning Research Engineer at Konta, an AI startup based in Casablanca. he holds an engineering degree in Big Data and AI and it’s currently enrolled in a PhD program focused on business document understanding at Chouaib Doukkali University. In his day to day activities, Kevin train, deploy and monitor in production machine learning models. With his friends, they lead TakwimuLab, an organisation working on training the next young, french speaking, west africans talents in AI and solving real-life problems with their AI skills. In his spare time, Kevin also create programming and AI educational content on Youtube and play video games.
Researcher Profile: Momboladji Balogoun
Momboladji BALOGOUN is the Data Analyst of Gozem, a company providing ride-hailing and other services in West and Central Africa. He is a former Data Scientist at Rintio, an IT startup based in Benin, that uses data and AI to create business solutions for other enterprises. Momboladji holds a M.Sc. degree in Applied Statistics from ICMPA UNESCO Chair, Cotonou, and migrated to the Data Science field after having attended a regional Big Data Bootcamp in his country Benin. He aims to pursue a Ph.D. program on low resources languages speech to speech translation. Bola created Takwimu LAB in August 2019, and he leads it currently with 3 other friends in order to promote Data Science in their countries, but also the creation and the use of AI to solve real-life problems in their communities. His hobbies are: Reading, Documentaries, and Tourism.
Researcher Profile: Godson Kalipe
Godson started in the IT field with software engineering with a specialization on mobile applications. After his bachelor in 2015, he worked for a year as web and mobile application developer before joining a master in India in Big Data Analytics. His master thesis consisted comparative analysis of international news impact on economic indicators of African countries using news Data, Google Cloud storage and visualization assets. After his Master,
in 2019, he gained a first experience as Data Engineer creating data ingestion pipelines for real time sensor data at Activa Inc, India. He parallely has been working with Takwimu Lab on various projects with the aim of bringing AI powered solutions to common african problems and make the field more popular in the west African francophone industry.
Researcher Profile: Jamiil Toure
Jamiil is a design engineer in electrical engineering from Ecole Polytechnique d’Abomey-Calavi (EPAC), Benin in 2015 and a master graduate in mathematical sciences from African School of Mathematical Sciences (AIMS) Senegal in 2018. Passionate of languages and Natural Language Processing (NLP), he contributes to the Masakhane project by working on the creation of a dataset for the language Dendi.
Meanwhile, he complements his education on NLP concepts via online courses, events, conferences for a future research career in NLP. With his friends at Takwimu Lab they work at creating active learning and working environments to foster the applications and usages of AI to tackle real-life problems. Currently, Jamiil is a consultant in Big Data at Cepei – a think tank based in Bogota that promotes dialogue, debate, knowledge and multi-stakeholder participation in global agendas and sustainable development.
Partners
Partners in Cracking the Language Barrier for a Multilingual Africa
Disclaimer
The designations employed and the presentation of material on these map do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or any area or of its authorities, or concerning the delimitation of its frontiers or boundaries. Final boundary between the Republic of Sudan and the Republic of South Sudan has not yet been determined. Final status of the Abyei area is not yet determined.