The networks founding members also include the UNESCO Chair in Analytics and Data Science at University of Essex (ES), UNESCO Chair in AI & Data Science at The Hague University of Applied Sciences (THUAS), and the Regional Center for Studies on the Development of the Information Society – CETIC (Brazil) under the auspices of UNESCO.
The initial partners are coming from Slovenia, Australia, Andorra, Brazil, Chile, Finland, France, Ghana, Hungary, Iceland, Italy, Kenya, Mexico, Netherlands, Nigeria, Pakistan, Senegal, South Africa, Spain, Sweden, Tanzania, UK and USA.
NAIXUS was launched as multi-stakeholder initiative with the goal of bridging the gap between AI and sustainable development at the side event of the STI 2022 Forum on May 4, 2022. Speakers at the event included Ambassador Boštjan Malovrh, Permanent Representative of Slovenia to the UN in New York, Marielza Oliveira, Communications and Information Sector, IFAP Secretary, UNESCO, and John Shawe-Taylor, IRCAI Director.
The main part of the agenda consisted of short presentations introducing the history, goal, objectives, composition, activities, programmes and technological focus of the network with supporters and initial partners of the initiative to build this global network of excellence centres in sustainable development. The recording of the event is available here.
Launching a Global Network of AI Excellence Centres in Sustainable Development – Side Event At The Sti Forum – 7th Multi-Stakeholder Forum On Science, Technology And Innovation For The Sustainable Development Goals
The Knowledge 4 All Foundation is proud to have been acknowledged by the Masakhane Research Foundation in their recent influential publications advancing Natural Language Processing (NLP) for African languages. These publications highlight the Foundation’s pivotal contributions to developing datasets and fostering AI innovation across the continent.
“A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation” (NAACL 2022) This paper explores how a small number of translations can significantly enhance pre-trained models for African news translation, addressing the scarcity of African-language datasets. Read the full paper here.
“MasakhaNER 2.0: Africa-centric Transfer Learning for Named Entity Recognition” (EMNLP 2022) This work presents MasakhaNER 2.0, a model leveraging Africa-centric transfer learning techniques for Named Entity Recognition (NER) in African languages, providing a vital resource for African NLP tasks. Read the full paper here.
“MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages” (ACL 2023) This research introduces MasakhaPOS, which addresses the challenges of Part-of-Speech (POS) tagging in the diverse and underrepresented African linguistic landscape. Read the full paper here.
These projects, made possible through collaborative efforts and the contributions of Knowledge 4 All Foundation, have significantly advanced NLP for African languages, paving the way for inclusive and representative AI solutions.
The Foundation expresses its gratitude to Masakhane Research Foundation and remains committed to supporting initiatives that promote linguistic diversity, inclusivity, and technological progress for African communities. Together, these partnerships exemplify the power of global collaboration in driving impactful AI research and development.
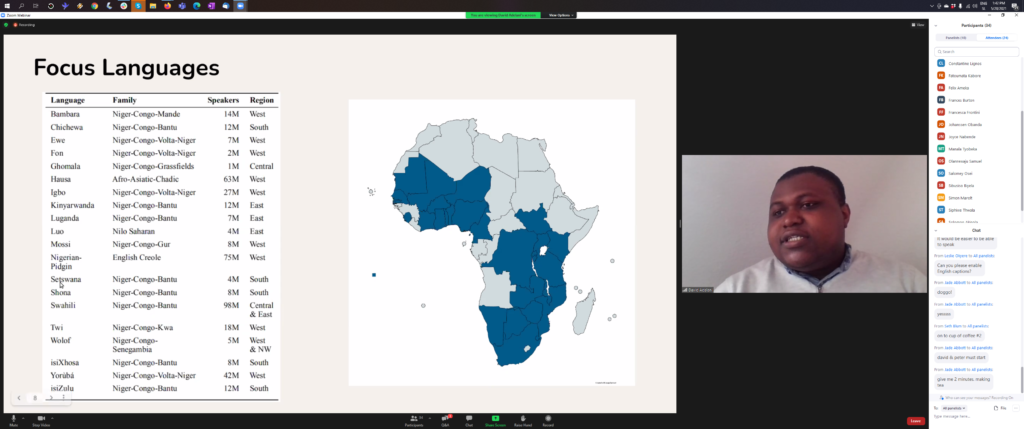
We are very happy to announce that one of our Lacuna funded projects titled Named Entity Recognition and parts of Speech Datasets for African Languages has been successfully finished. At the start of our work, none of the languages associated with this project had a manually prepared NER dataset. Also, only a very small subset of languages in South Africa, and Yoruba, Naija, Wolof, and Bambara had Part-of-speech (POS) datasets. This project has therefore provided the first carefully prepared NER and POS datasets for 20 African languages. The project initially achieved new parallel texts (up to 8000 parallel sentences) for at least 8 low-resourced languages. The parallel texts are a very valuable resource for bilingual NLP applications. The results will be uploaded to the Masakhane Github repository.
This was the EU-funded HumanE-AI-Net project meeting which brought together leading European research centres, universities and industrial enterprises into a network of centres of excellence. Leading global artificial intelligence (AI) laboratories collaborate with key players in areas, such as human-computer interaction, cognitive, social and complexity sciences. The project is looking forward to drive researchers out of their narrowly focused field and connect them with people exploring AI on a much wider scale. The challenge is to develop robust, trustworthy AI systems that can ‘understand’ humans, adapt to complex real-world environments and interact appropriately in complex social settings. HumanE-AI-Net will lay the foundations for designing the principles for a new science that will make AI based on European values and closer to Europeans.
HumaneAI-Net meeting, April 12-14, 2022 Venice, ItalyHumaneAI-Net meeting, April 12-14, 2022 Venice, ItalyHumaneAI-Net meeting, April 12-14, 2022 Venice, ItalyHumaneAI-Net meeting, April 12-14, 2022 Venice, ItalyHumaneAI-Net meeting, April 12-14, 2022 Venice, Italy
We are excited to be launching our collaborative approach to enhancing the European OER ecosystem with a series of events this Autumn! The events are great opportunities to network with relevant stakeholder groups and lead the discourse around the future of education and training in Europe. Read more here: https://encoreproject.eu/2021/09/02/launching-the-encore-oer-ecosystem/
Based on recommendations by the European Commission and UNESCO, we are developing the new European OER ecosystem. Help us shape the network by participating in this short survey.
This study contributes to the European Network for Catalysing Open Resources in Education (ENCORE+), a pan-European Knowledge Alliance funded under the Erasmus+ programme. The project is an initiative of the International Council for Distance Education (ICDE) as well as several higher education instutions and businesses across Europe and will run from 2021 to 2023 to support the modernisation of education in the European area through OER.
The project has developed a commoditized set of tools and systems that enable the ingestion of OER material into the X5GON registry including semantic cross-lingual indexing of materials, automatic transcription and translation of recordings, assessment of how engaging the material is, and potentially how it might sequence with other OERs.
Further, methods for automatically estimating the knowledge of users based on their track record of viewing different OERs enables the system to recommend content that is likely to engage and prove useful for learners and teachers.
X5GON ending in the Horizon 2020 programme, but work still continues
For example, a moodle plug-in can provide such recommendations at the level of a particular course, while the X5learn system can make recommendations to individual learners based on their earlier viewing experience.
The project has actively engaged with OER sites and developed systems to assist with the incorporation of OERs into the X5GON registry significantly growing the number of sites and materials that are indexed by the X5gon tools.
Work partially funded by K4A has won the inaugural 2021 Wikimedia Foundation Research Award of the Year with the paper “Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages” and the Masakhane Community
This paper and the Masakhane community have attempted to fundamentally change how we approach the challenge of “low-resourced languages” in Africa via a set of projects funded by K4A, with the support of UNESCO, IDRC, and GIZ. The research describes a novel approach for participatory research around machine translation for African languages. The authors show how this approach can overcome the challenges these languages face to join the Web and some of the technologies other languages benefit from today.
The work of the authors and the community is an inspiring example of work towards Knowledge Equity, one of the two main pillars of the 2030 Wikimedia Movement Strategy. “As a social movement, we will focus our efforts on the knowledge and communities that have been left out by structures of power and privilege. We will welcome people from every background to build strong and diverse communities. We will break down the social, political, and technical barriers preventing people from accessing and contributing to free knowledge.”
We cannot think of a better or more inspiring example of a project we have been involved in the last couple of years.
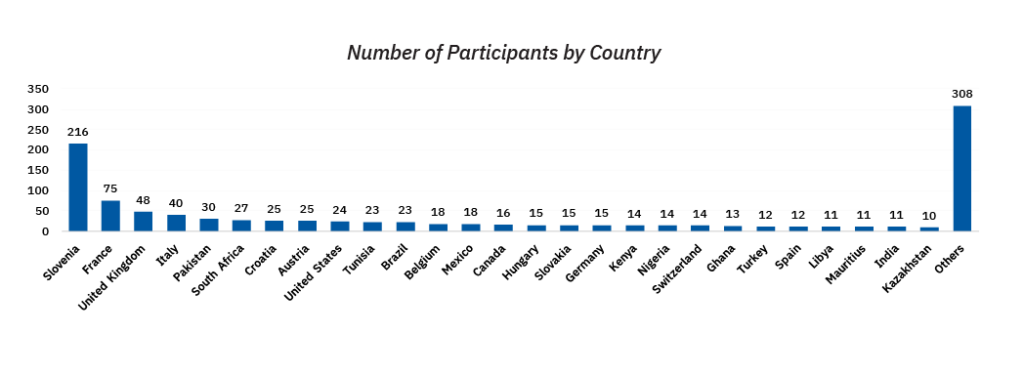
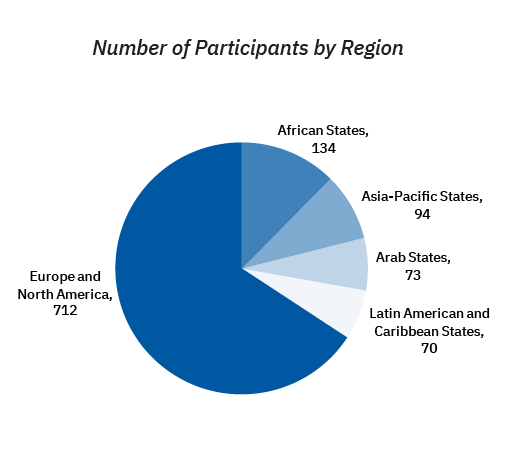
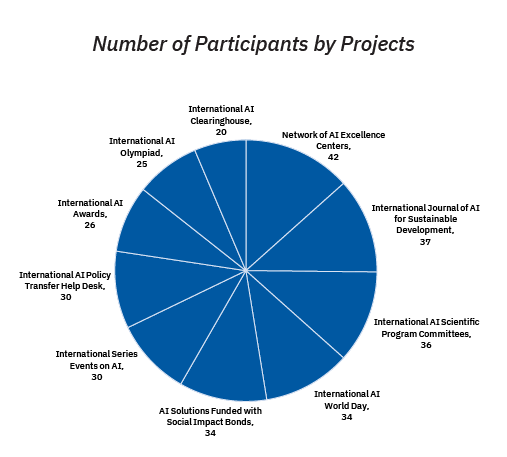
On March 29 and 30 2021, the IRCAI launch event took place. 1083 registered participants from 123 countries attended and were addressed by esteemed speakers on the first day of the event. Participants came from all geographical regions of United Nations: African, Asian-Pacific, Eastern European, Latin American and Caribbean and Western European states. Non-registered participants were also invited to watch the event via live streaming on YouTube. The launch was created with input from 33 active speakers and panelists.
In his speech, the President of the Republic of Slovenia, Mr. Borut Pahor, emphasized that the establishment of IRCAI in Ljubljana is a great recognition for Slovenian researchers and the Jožef Stefan Institute who have been working on artificial intelligence in Slovenia for several decades. According to President Pahor, artificial intelligence is a tool for a better life and offers great opportunities “for progress, for more accessible and efficient public services, quality education and better access to information, and helps us fight climate change, introduce new forms of mobility and use energy more efficiently.”
The Director-General of the United Nations Educational, Scientific and Cultural Organization (UNESCO), Ms Audrey Azoulay, who attended the event live from Paris, regretted that she could not be there live as originally planned and welcomed IRCAI to the UNESCO family. “IRCAI has become a space that directs academic and human resources to research topics within the mandate of UNESCO, which, as you know, includes education, culture, science and information,” adding that despite the large number of UNESCO centers, none yet deals with artificial intelligence. “Thanks to IRCAI, we now have the support of an entire team that is directing its diverse skills to ensure that artificial intelligence is used in a way that serves the common good. We are fortunate to have an ally like this to help make our ambitions reality,” she added, explaining the important role IRCAI played in drafting the UNESCO Recommendation on Ethical Artificial Intelligence and personally thanking the team for their efforts in leading the regional consultation on the draft recommendation. “We have already had a glimpse of the potential of this partnership. This inauguration is therefore very promising,” she concluded.
The Minister of Education, Science and Sport of Slovenia,Prof Simona Kustec stressed the importance of cooperation in creating opportunities to address current challenges, including through artificial intelligence, and called on all participants to work together. The Minister of Public Administration of Slovenia, Mr Boštjan Koritnik stressed that “Slovenia aims for a high quality and ethical use of artificial intelligence that citizens can trust” and emphasized that artificial intelligence will be one of the main priorities during the Slovenian EU Presidency.
The development of artificial intelligence in Slovenia was also highlighted by prof. Boštjan Zalar, Director of the Jožef Stefan Institute, who stressed that the Institute has a 40-year history in the development of artificial intelligence, over 70 major projects in various departments of the Institute and that in his opinion IRCAI can further strengthen these achievements.
Support for IRCAI was also expressed by the representative of European Commission with which IRCAI has many strategic synergies. Anthony Whelan , Digital Policy Adviser from the cabinet of European Commission President Ursula von der Leyen noted, “It is indeed a nice coincidence that the Slovenian Presidency is preparing to work with such an excellent asset at its doorstep, and we hope that this will also serve as a flagship for international efforts.“
The sequence of events leading to the establishment of IRCAI and the results of the Center’s work so far were presented by its Director, Prof. John Shawe-Taylor. “IRCAI has already established active cooperation with a wide range of international organizations, which it intends to further strengthen and expand,” he said in his speech. Among other things, he called for active participation through projects listed on the Center’s website.
On the first day, a panel discussion, which included several speakers from African countries, focused on building a global artificial intelligence community. The second day of the event focused on presentations of the results of IRCAI activities, opportunities for collaboration, and the use of artificial intelligence tools to support the achievement of Sustainable Development Goals. Presentations were given by IRCAI Program Committee representatives Aidan O’Sullivan, Colin de La Higuera, Catherine Holloway and Delmiro Fernandez-Reyes.
Analyzes of 6 Regional Consultations on UNESCO recommendation on AIethics and IRCAI ethics andregulatory approaches were presented alongside panel discussions on the issues of the need for policy action on AI. IRCAI Funding and Innovation Program: Social Impact Bonds, AI policies around the world and AI Global Observatory were also presented by IRCAImember organizations Daniel Miodovnik, Mark Minevich and Marko Grobelnik respectively. The presentations included 5 reports co-authored by IRCAI representatives: Artificial Intelligence in Sub-Saharan Africa, Artificial Intelligence Needs Assessment Survey in Africa, UNESCO Ethics of AI Recommendation Regional Consultations, Opinion Series Reports: UNESCO Ethics of AI Recommendation Regional Consultations, Responsible Artificial Intelligence in Sub-Saharan Africa and Powering Inclusion: Artificial Intelligence and Assistive Technology.
A call for collaboration has also been launched to join IRCAI, which is actively working on 10 projects to be implemented by 2021. These are all designed to scale and deploy AI to achieve the Global Challenges that the Center has set out to achieve. IRCAI is seeking partnerships with, International Organizations, governments, companies, NGOs, universities, research institutes, AI consortia and government agencies around the world to implement these projects.
On social media, Arabic speakers tend to express themselves in their own local dialect. To do so, Tunisians use “Tunisian Arabizi”, which consists in supplementing numerals to the Latin script rather than the Arabic alphabet.
In the African continent, analytical studies based on Deep Learning are data hungry. To the best of our knowledge, no annotated Tunisian Arabizi dataset exists.
Twitter, Facebook and other micro-blogging systems are becoming a rich source of feedback information in several vital sectors, such as politics, economics, sports and other matters of general interest. Our dataset is taken from people expressing themselves in their own Tunisian Dialect using Tunisian Arabizi.
TUNIZI is composed of one instance presented as text comments collected from Social Media, annotated as positive, negative or neutral. This data does not include any confidential information. However, negative comments may include offensive or insulting content.
TUNIZI dataset is used in all iCompass products that are using the Tunisian Dialect. TUNIZI is used in a Sentiment Analysis project dedicated for the e-reputation and also for all Tunisian chatbots that are able to understand the Tunisian Arabizi and reply using it.
Team
TUNIZI Dataset is collected, preprocessed and annotated by iCompass team, the Tunisian Startup speciallized in NLP/NLU. The team composed of academics and engineers specialized in Information technology, mathematics and linguistics were all dedicated to ensure the success of the project. iCompass can be contacted through emails or through the website: www.icompass.tn
Implementation
Data Collection: TUNIZI is collected from comments on Social Media platforms. All data was directly observable and did not require other data to be inferred from. Our dataset is taken from people expressing themselves in their own Tunisian Dialect using Arabizi. This dataset relates directly to Tunisians from different regions, different ages and different genders. Our dataset is collected anonymously and contains no information about users identity.
Data Preprocessing & Annotation: TUNIZI was preprocessed by removing links, emoji symbols and punctuation. Annotation was then performed by five Tunisian native speakers, three males and two females at a higher education level (Master/PhD).
Distribution and Maintenance: TUNIZI dataset is made public for all upcoming research and development activitieson Github. TUNIZI is maintained by iCompass team that can be contacted through emails or through the Github repository. Updates will be available on the same Github link.
Conclusion: As the interest in Natural Language Processing, particularly for African languages is growing, a natural future step would involve building Arabizi datasets for other underrepresented north African dialects such as Algerian and Moroccan.