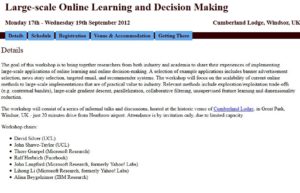
Workshop on Statistical Physics of Inference and Control Theory
September 12-16 2012 Granade, Spain
The topic of the present workshop is stochastic optimal control theory and its relations to machine learning and robotics, statistical mechanics, quantum theory and the theory of large deviations.
For many years, the deterministic control theory has dominated control applications in robotics and autonomous systems, mainly because of computational restrictions. Relatively recently, there have been several approaches to restate the stochastic optimal control computation as an inference problem and to obtain efficient solutions using approximate inference. In these control theories, concepts from classical mechanics and control theory (variational calculus and Hamilton-Jacobi equations) and stochastic processes and large deviations theory (Feynman-Kac formula) are intimately related. This approach provides novel insights for the design of efficient algorithms to efficiently compute optimal stochastic control solutions in robotics.
The Hamilton Jacobi equation also plays a crucial role in the computation of non-equilibrium large deviations. In recent developments, this large deviation theory has provided a rather general framework in which the macrobehavior of non-equilibrium systems can be studied. In addition, there is a connection between these control formulations and Nelsons stochastic mechanics, which aims to provide a particle interpretation of quantum mechanics.
This workshop brings together researchers from control theory, machine learning, physics and mathematics to explore these connections.
Topics:
- Stochastic optimal control theory
- Stochastic processes
- Non-equilibrium large deviations
- Stochastic quantum theories and quantum control
- Applications in robotics


Misha Chertkov (Los Alamos)
Bert Kappen ( Nijmegen)
Frank Redig (Delft)
Riccardo Zecchina (Torino)
Joaquin Torres (Granada)
Joaquin Marro (Granada)